02:程序架构全解——从项目结构到并发搜索实现
在上一篇文章中,我们了解了Go语言的设计哲学和核心特性。本篇我们将通过一个完整的、可运行的Go程序,按照真实项目的开发逻辑(需求→设计→抽象→实现→组装)一步步构建一个并发搜索引擎——从多个数据源(RSS、JSON等)拉取数据,根据搜索词进行匹配,并将结果展示在终端。
通过剖析这个程序,你将学习到:
- 如何从需求出发拆解Go项目的设计步骤
- 如何设计可扩展的接口和数据结构(接口先行)
- 如何按职责拆分模块/包,组织标准项目结构
- 如何启动和同步goroutine,使用通道进行通信
- 如何通过接口编写通用、可扩展的代码
- 如何处理常见的错误和日志
让我们从需求分析开始,一步步拆解这个完整的Go程序。
本篇核心收获
- 掌握“需求→抽象→实现→组装”的Go项目开发流程
- 理解“接口先行”的设计思想(先定扩展点,再做具体实现)
- 学会按职责拆分包和模块,而非单纯按文件类型
- 掌握goroutine并发模式与WaitGroup同步机制
- 深入理解通道(channel)在goroutine间传递数据的方式
- 了解闭包在并发场景下的使用陷阱及解决方案
需求分析与核心目标(开发的起点)
在写任何代码前,先明确“要解决什么问题”,这是所有设计的基础:
核心需求
实现一个多数据源并发搜索引擎,满足:
- 支持从RSS等不同类型数据源拉取数据
- 对每个数据源并发执行搜索,提高效率
- 可灵活扩展新的数据源类型(如JSON/CSV),无需改动核心逻辑
- 统一收集并展示所有搜索结果
- 完善的错误处理和日志输出
关键约束
- 遵循Go的工程化规范(包结构、命名、错误处理)
- 并发安全,结果收集不丢数据
- 代码可复用、可扩展(开闭原则)
整体架构设计(拆分核心流程)
基于需求,先设计程序的核心执行流程(先定骨架,再填细节):
初始化(注册匹配器)→ 加载数据源配置 → 并发搜索(每个数据源一个goroutine)→ 收集结果 → 展示结果
图1清晰地展示了整个程序的执行流程:
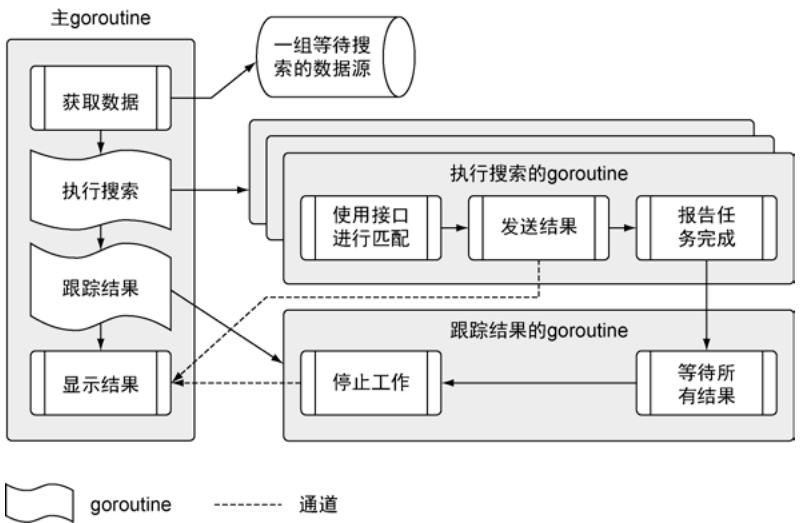
图1:程序架构流程图
再基于流程拆分模块边界(职责单一原则):
| 模块职责 | 对应包/文件 | 设计目的 |
|---|---|---|
| 定义核心接口/数据结构 | search/match.go | 定扩展点,统一结果和匹配行为 |
| 加载数据源配置 | search/feed.go | 解耦数据读取与业务逻辑 |
| 实现具体数据源匹配器 | matchers/rss.go | 扩展点的具体实现 |
| 兜底匹配器(默认实现) | search/default.go | 防止无匹配器时程序崩溃 |
| 核心并发控制逻辑 | search/search.go | 调度并发搜索、收集结果 |
| 程序入口(组装所有模块) | main.go | 初始化+启动核心逻辑 |
项目结构与核心抽象设计
3.1 项目目录结构
如下结构展示了这个程序的完整项目组织:
- data
data.json # 包含一组数据源配置
- matchers
rss.go # 搜索RSS源的匹配器实现
- search
default.go # 默认匹配器(兜底方案)
feed.go # 读取JSON数据文件
match.go # 定义Matcher接口和结果展示
search.go # 核心搜索控制逻辑
main.go # 程序入口设计要点:
- 每个文件夹对应一个包(package),包名与文件夹名相同
main包是程序入口,必须包含main函数- 通过包名实现代码的模块化隔离和复用
3.2 核心抽象设计(先定骨架)
Go语言强调“接口先行”,先设计核心接口和数据结构(程序的“骨架”),再实现具体逻辑。
数据结构(承载数据)
// search/feed.go - 数据源结构(适配JSON配置)
type Feed struct {
Name string `json:"site"` // JSON字段映射
URI string `json:"link"`
Type string `json:"type"` // 数据源类型(关联匹配器)
}
// search/match.go - 结果结构(统一输出)
type Result struct {
Field string // 匹配的字段(标题/描述)
Content string // 匹配的内容
}核心接口(扩展点)
为了支持“灵活扩展数据源”,设计Matcher接口(所有匹配器必须实现该接口):
// search/match.go - 接口定义
type Matcher interface {
Search(feed *Feed, searchTerm string) ([]*Result, error)
}设计决策:
- 接口只包含一个方法,遵循“小接口原则”(Go的接口设计精髓)
- 无需显式声明实现,隐式适配(降低耦合)
- 所有数据源匹配器都实现该接口,核心逻辑只需依赖接口
匹配器注册机制(解耦注册与使用)
// search/search.go - 注册表
var matchers = make(map[string]Matcher)
func Register(feedType string, matcher Matcher) {
if _, exists := matchers[feedType]; exists {
log.Fatalln(feedType, "Matcher already registered")
}
matchers[feedType] = matcher
}设计决策:
- 用map做“类型→匹配器”的映射,O(1)查找效率
- 包内私有map+公有Register函数,保证安全性和扩展性
main包——程序入口(组装所有模块)
4.1 main.go完整代码
package main
import (
"log"
"os"
_ "github.com/goinaction/code/chapter2/sample/matchers"
"github.com/goinaction/code/chapter2/sample/search"
)
// init在main之前调用
func init() {
log.SetOutput(os.Stdout)
}
// main是整个程序的入口
func main() {
search.Run("president")
}4.2 核心特性解析
- 匿名导入(第07行):
_ "matchers"只触发matchers包中的init函数(注册RSS匹配器),不引用其他标识符,解耦“注册”和“使用”。 - init函数(第11-15行):在
main之前自动执行,用于初始化配置(如日志输出)。 - main函数(第17-18行):保持简洁,只调用
search.Run启动核心逻辑。
search包——核心业务逻辑
search包是整个程序的核心,包含4个代码文件,各司其职。
5.1 search.go——主控制逻辑(并发调度)
包级变量与Run函数
package search
import (
"log"
"sync"
)
var matchers = make(map[string]Matcher)
// Run执行搜索逻辑
func Run(searchTerm string) {
// 获取需要搜索的数据源列表
feeds, err := RetrieveFeeds()
if err != nil {
log.Fatal(err)
}
// 创建无缓冲通道,接收匹配后的结果
results := make(chan *Result)
// 构造WaitGroup,等待所有数据源处理完成
var waitGroup sync.WaitGroup
waitGroup.Add(len(feeds))
// 为每个数据源启动一个goroutine来查找结果
for _, feed := range feeds {
matcher, exists := matchers[feed.Type]
if !exists {
matcher = matchers["default"]
}
// 启动goroutine(以参数形式传递,避免闭包陷阱)
go func(matcher Matcher, feed *Feed) {
Match(matcher, feed, searchTerm, results)
waitGroup.Done()
}(matcher, feed)
}
// 启动监控goroutine:等待所有搜索完成后关闭通道
go func() {
waitGroup.Wait()
close(results)
}()
// 显示结果(通道关闭后循环自动退出)
Display(results)
}并发设计要点:
- 无缓冲通道:天然同步,保证结果不丢失。
- WaitGroup:精准控制所有搜索goroutine完成。
- 闭包传参:将变量作为参数传入匿名函数,每个goroutine获得独立副本,避免循环变量共享的陷阱。
- 通道关闭:由监控goroutine负责,保证
Display能正常退出。
5.2 feed.go——数据源加载
package search
import (
"encoding/json"
"os"
)
const dataFile = "data/data.json"
type Feed struct {
Name string `json:"site"`
URI string `json:"link"`
Type string `json:"type"`
}
// RetrieveFeeds读取并反序列化源数据文件
func RetrieveFeeds() ([]*Feed, error) {
file, err := os.Open(dataFile)
if err != nil {
return nil, err
}
defer file.Close() // 确保函数返回前关闭文件
var feeds []*Feed
err = json.NewDecoder(file).Decode(&feeds)
return feeds, err
}设计决策:
- 结构体标签:实现JSON字段与Go结构体的解耦。
- defer:让资源管理代码紧邻资源获取,提高可读性且防止泄漏。
5.3 match.go——接口定义与结果处理
package search
// Result保存搜索的结果
type Result struct {
Field string
Content string
}
// Matcher接口(扩展点)
type Matcher interface {
Search(feed *Feed, searchTerm string) ([]*Result, error)
}
// Match执行搜索并将结果写入通道
func Match(matcher Matcher, feed *Feed, searchTerm string, results chan<- *Result) {
searchResults, err := matcher.Search(feed, searchTerm)
if err != nil {
log.Println(err)
return
}
for _, result := range searchResults {
results <- result
}
}
// Display从通道读取结果并输出
func Display(results chan *Result) {
for result := range results {
fmt.Printf("%s:\n%s\n\n", result.Field, result.Content)
}
}只写通道(第15行):chan<- *Result限制函数只能向通道发送数据,提高类型安全。
range与通道:for result := range results持续读取直到通道关闭,为空时阻塞,关闭时自动退出。
5.4 default.go——默认匹配器(兜底实现)
package search
type defaultMatcher struct{}
func init() {
var matcher defaultMatcher
Register("default", matcher)
}
func (m defaultMatcher) Search(feed *Feed, searchTerm string) ([]*Result, error) {
return nil, nil // 空实现,保证程序不会因无匹配器而崩溃
}空结构体:struct{}不占用内存,适用于无状态的类型。
RSS匹配器——具体实现(扩展点实例)
RSS匹配器位于matchers包中,通过main.go的匿名导入被加载。
6.1 RSS数据结构(适配XML)
package matchers
import (
"encoding/xml"
"net/http"
"regexp"
"github.com/goinaction/code/chapter2/sample/search"
)
type (
item struct {
Title string `xml:"title"`
Description string `xml:"description"`
// ... 其他字段
}
channel struct {
Item []item `xml:"item"`
}
rssDocument struct {
Channel channel `xml:"channel"`
}
)
type rssMatcher struct{}
func init() {
var matcher rssMatcher
search.Register("rss", matcher)
}6.2 Search方法——核心匹配逻辑
func (m rssMatcher) Search(feed *search.Feed, searchTerm string) ([]*search.Result, error) {
var results []*search.Result
// 1. 拉取RSS数据
resp, err := http.Get(feed.URI)
if err != nil {
return nil, err
}
defer resp.Body.Close()
// 2. 解析XML
var document rssDocument
err = xml.NewDecoder(resp.Body).Decode(&document)
if err != nil {
return nil, err
}
// 3. 正则匹配搜索词
for _, item := range document.Channel.Item {
matched, _ := regexp.MatchString(searchTerm, item.Title)
if matched {
results = append(results, &search.Result{
Field: "Title",
Content: item.Title,
})
}
// 同样匹配Description...
}
return results, nil
}设计要点:
- 通过
http.Get拉取数据,defer resp.Body.Close()确保连接关闭。 - XML解码使用结构体标签映射。
- 正则匹配后动态扩展切片(
append)。
完整执行流程回顾
串联所有组件,回顾程序的完整执行流程:
启动阶段:
main包被加载,执行所有init函数。default.go和rss.go的init分别注册默认匹配器和RSS匹配器。main.go的init设置日志输出。main函数被调用。
数据准备:
search.Run("president")被调用。RetrieveFeeds()读取data.json,返回Feed切片。
并发搜索:
- 创建
results通道和WaitGroup。 - 为每个Feed启动goroutine。
- 每个goroutine根据
Feed.Type获取对应的Matcher,调用Match执行搜索。 - 结果写入
results通道,然后调用waitGroup.Done()。
- 创建
监控与输出:
- 监控goroutine等待所有搜索完成,关闭
results通道。 Display函数从通道读取结果并输出。
- 监控goroutine等待所有搜索完成,关闭
程序终止:
- 所有结果输出完毕,
Display返回。 main函数返回,程序退出。
- 所有结果输出完毕,
核心知识点速记
- 包管理:每个文件夹一个包,main包生成可执行文件;大写标识符公开,小写私有。
- init函数:在main之前执行,用于初始化注册;匿名导入
_触发init但不引用包。 - 接口设计:隐式实现,小接口(单方法)命名以er结尾,先定接口后写实现。
- 并发模型:
go关键字启动goroutine;WaitGroup用于等待;通道用于通信。 - 闭包陷阱:在循环中启动goroutine时,务必通过参数传递循环变量,避免共享同一个引用。
- defer:延迟执行,用于资源释放(文件、网络连接),确保即使panic也会执行。
- 通道:
make(chan Type)创建;<-发送和接收;close关闭通道;for range自动读取直到关闭。 - 错误处理:函数返回
error,调用方检查;log.Fatal输出错误并退出。 - JSON/XML解码:结构体标签定义映射;
NewDecoder().Decode()流式解码。 - 切片:动态数组;
append追加元素;for range遍历。
文末小结
本篇我们按“真实开发逻辑”重构了整个并发搜索引擎的设计与实现过程——从需求分析开始,先搭骨架(接口/数据结构),再做零件(匹配器),然后实现核心逻辑(并发控制),最后组装成完整程序(main包)。
这种“先设计后实现、先抽象后具体”的思路,是Go项目开发的核心方法论:
- 接口是扩展的核心:小接口带来高灵活性,新增数据源只需实现
Matcher接口并注册。 - 包是模块化的核心:职责单一带来高可维护性,每个文件只做一件事。
- 并发是Go的优势:goroutine+通道让并发逻辑更简洁,配合
WaitGroup轻松同步。 - 工程化是落地的关键:
init、defer、匿名导入等特性保证程序的鲁棒性。
掌握这个设计流程和并发模式,你不仅能看懂Go项目的代码,更能从零开始设计和实现可扩展、可维护的Go程序。
配套检测题
一、选择题
1. Go项目的包结构规则是:
A. 一个文件夹可以包含多个包
B. 一个目录一个包,包名通常与目录名相同
C. 包名必须与文件名相同
D. 不同目录的包不能同名
2. 关于init函数,以下说法正确的是:
A. 可以在代码中手动调用
B. 在main之前自动执行,每个包可以有多个
C. 执行顺序随机
D. 只在导入时执行,不能在定义它的包中执行
3. WaitGroup的Add、Done、Wait方法作用分别是:
A. Add增加计数、Done减少计数、Wait阻塞等待归零
B. Add设置计数、Done完成、Wait等待完成
C. Add添加任务、Done完成任务、Wait等待所有任务
D. Add添加 goroutine、Done关闭通道、Wait等待结束
4. 关于闭包与循环变量,以下说法正确的是:
A. 直接在闭包中使用循环变量是安全的
B. 循环变量会被所有闭包共享,可能导致问题
C. Go 1.22之前闭包使用循环变量是安全的
D. 闭包不能访问外部变量
5. 使用defer的正确场景是:
A. 打开文件后,使用defer关闭确保释放
B. defer不能用在循环中
C. defer只执行最后注册的一个
D. defer不能与匿名函数一起使用
二、填空题
6. Go程序的入口包名是________。
7. 匿名导入_ "matchers"的作用是________。
8. 通道按是否带缓冲分为________和________。
9. chan<-表示________(只发送/只接收)的通道。
10. 在Go的接口设计哲学中,接口应该________(大/小),以________结尾命名。
三、问答题
11. 解释"接口先行"的设计思想,并说明其好处。
12. 说明以下代码的问题并给出正确写法:
results := make([]*Result, 0)
for _, feed := range feeds {
go func() {
matched, _ := regexp.MatchString(searchTerm, feed.Name)
if matched {
results = append(results, &Result{Content: feed.Name})
}
}()
}13. 说明无缓冲通道和有缓冲通道的区别。
14. 为什么推荐使用包级变量+函数的方式管理注册,而不是直接使用全局变量?
四、编程题
15. 编写代码实现以下功能:
// 1. 定义Feed结构体(Name, URI, Type字段)
// 2. 定义Result结构体(Field, Content字段)
// 3. 定义Matcher接口,包含Search方法
// 4. 实现一个defaultMatcher空实现
// 5. 编写main函数演示注册和使用16. 编写并发程序模拟日志处理:
// 1. 创建带缓冲的日志通道(缓冲大小3)
// 2. 启动3个goroutine并发处理日志,每个等待随机时间后处理
// 3. 主goroutine发送5条日志后关闭通道
// 4. 使用sync.WaitGroup等待所有处理完成
// 5. 打印"All logs processed"17. 编写程序演示只写通道的用法:
// 1. 定义sendData函数,只写通道
// 2. 在函数内写入3个数字到通道
// 3. main函数中创建通道,调用sendData
// 4. 接收并打印所有数据五、综合应用题
18. 参考第2篇的并发搜索引擎,设计一个简化的程序:
// 1. 定义Matcher接口(Search方法)
// 2. 实现两种匹配器:
// - exactMatcher:精确匹配
// - regexMatcher:正则匹配
// 3. 使用注册机制管理匹配器
// 4. main函数演示两种匹配器的使用
// 5. 说明匹配器注册机制如何实现了开闭原则19. 分析以下代码的执行流程和输出:
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var wg sync.WaitGroup
ch := make(chan int)
wg.Add(2)
go func() {
defer wg.Done()
for i := 0; i < 3; i++ {
ch <- i
time.Sleep(100 * time.Millisecond)
}
}()
go func() {
defer wg.Done()
for i := 3; i < 6; i++ {
ch <- i
time.Sleep(100 * time.Millisecond)
}
}()
go func() {
wg.Wait()
close(ch)
}()
for v := range ch {
fmt.Printf("Received: %d\n", v)
}
fmt.Println("Done")
}答案
一、选择题答案
1. B 一个目录一个包,包名与目录名相同是Go的基本规则。不同目录的包可以同名,导入时通过全路径区分。
2. B init函数在main之前自动执行,每个包可以有多个init函数,按导入顺序执行(先导入的包的init先执行)。
3. A Add增加WaitGroup的计数器,Done减少计数器(通常在goroutine结束时调用),Wait阻塞直到计数器归零。
4. B 直接在闭包中使用循环变量会导致所有闭包共享同一个变量,在Go 1.22之前这是常见陷阱。正确做法是将循环变量作为参数传入闭包。
5. A defer用于资源释放,确保函数返回前执行清理工作,如关闭文件、释放连接等。
二、填空题答案
6. main
7. 只触发matchers包中的init函数(注册RSS匹配器),不引用其他标识符
8. 无缓冲通道;有缓冲通道
9. 只发送
10. 小;er
三、问答题答案
11. "接口先行"是指在实现具体功能之前,先设计程序需要的接口(扩展点),明确组件之间的契约,再实现具体逻辑。这种做法的优点:1)明确边界和依赖关系;2)便于并行开发;3)支持灵活扩展,新增实现只需实现接口无需修改调用方;4)提高代码的可测试性。
12. 问题:闭包直接引用循环变量feed,所有goroutine共享同一个feed变量,当循环结束时,goroutine才开始执行,此时feed指向最后一个元素。
正确写法:将循环变量作为参数传入闭包
for _, feed := range feeds {
go func(f Feed) {
matched, _ := regexp.MatchString(searchTerm, f.Name)
if matched {
results = append(results, &Result{Content: f.Name})
}
}(feed) // 作为参数传入
}13. 无缓冲通道:make(chan T),发送和接收必须同时准备好,否则阻塞。天然同步,不会有数据丢失。有缓冲通道:make(chan T, n),可以存储n个数据,发送时只在新元素加入前阻塞,接收时只在通道空时阻塞。缓冲通道提供了一定的异步能力。
14. 包级变量+函数的方式提供了更好的封装性和安全性:变量是私有的,只能通过公开函数访问;可以在函数内添加验证逻辑(如检查重复注册);便于后续扩展(如添加日志、延迟初始化等)。
四、编程题答案
15.
package main
import "fmt"
type Feed struct {
Name string
URI string
Type string
}
type Result struct {
Field string
Content string
}
type Matcher interface {
Search(feed *Feed, searchTerm string) ([]*Result, error)
}
type defaultMatcher struct{}
func init() {
Register("default", &defaultMatcher{})
}
func (m defaultMatcher) Search(feed *Feed, searchTerm string) ([]*Result, error) {
return nil, nil
}
var matchers = make(map[string]Matcher)
func Register(feedType string, matcher Matcher) {
matchers[feedType] = matcher
}
func main() {
m, ok := matchers["default"]
if ok {
fmt.Println("Default matcher registered")
results, _ := m.Search(&Feed{Name: "test"}, "test")
fmt.Println(results)
}
}16.
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
func processLog(log string, wg *sync.WaitGroup) {
defer wg.Done()
time.Sleep(time.Duration(rand.Intn(500)) * time.Millisecond)
fmt.Printf("Processed: %s\n", log)
}
func main() {
var wg sync.WaitGroup
ch := make(chan string, 3)
for i := 0; i < 3; i++ {
wg.Add(1)
go func() {
for log := range ch {
processLog(log, &wg)
}
}()
}
logs := []string{"log1", "log2", "log3", "log4", "log5"}
for _, log := range logs {
ch <- log
}
close(ch)
wg.Wait()
fmt.Println("All logs processed")
}17.
package main
import "fmt"
func sendData(ch chan<- int) {
for i := 1; i <= 3; i++ {
ch <- i
}
}
func main() {
ch := make(chan int)
go sendData(ch)
for v := range ch {
fmt.Println(v)
}
}五、综合应用题答案
18.
package main
import (
"fmt"
"regexp"
)
type Matcher interface {
Search(content string, term string) bool
}
var matchers = make(map[string]Matcher)
func Register(name string, m Matcher) {
matchers[name] = m
}
type exactMatcher struct{}
func (m exactMatcher) Search(content string, term string) bool {
return content == term
}
type regexMatcher struct{}
func (m regexMatcher) Search(content string, term string) bool {
matched, _ := regexp.MatchString(term, content)
return matched
}
func main() {
Register("exact", &exactMatcher{})
Register("regex", ®exMatcher{})
text := "hello world"
exact := matchers["exact"].Search(text, "hello")
fmt.Printf("Exact match 'hello': %v\n", exact)
regex := matchers["regex"].Search(text, "hello.*")
fmt.Printf("Regex match 'hello.*': %v\n", regex)
}开闭原则说明:新增匹配器只需实现Matcher接口并调用Register注册,无需修改Matcher接口或使用匹配器的代码。核心逻辑只依赖接口,不依赖具体实现。
19. 输出结果:
Received: 0
Received: 3
Received: 1
Received: 4
Received: 2
Received: 5
Done执行流程分析:
- 主goroutine启动两个发送goroutine,每个发送3个数字
- 启动监控goroutine等待两个发送goroutine完成后关闭通道
- 主goroutine从通道接收并打印,直到通道关闭
- 数字顺序不确定(取决于调度),但所有6个数字都会被接收
- 最后一个输出一定是"Done"(在通道关闭、Display返回后执行)