04:数据结构详解——数组、切片与映射的底层原理与实战用法
在上一篇文章中,我们完成了项目结构、包管理和工具链的学习。本篇内容,我们将深入Go语言的核心数据结构——数组、切片和映射。这三种结构是管理集合数据的基石,无论是处理数据库查询结果、解析JSON数组,还是构建缓存系统,都离不开它们。
通过本篇学习,你将掌握数组的内存布局与性能优势,理解切片如何基于数组实现动态扩容,学会映射的哈希原理与高效查询方法。我们还会深入分析切片扩容策略、指针传递的陷阱,以及如何安全地在函数间传递这些数据结构。所有内容都将结合底层实现,让你不仅“会用”,更懂得“为何如此设计”。
本篇核心收获
- 理解数组的连续内存布局及值语义特性
- 掌握切片的内部结构(指针、长度、容量)及动态扩容机制
- 熟练使用
append、len、cap操作切片 - 掌握切片的三种索引语法,避免共享底层数组带来的副作用
- 学会使用
range安全迭代切片和映射 - 理解映射的哈希表实现、桶的概念及键的限制条件
- 掌握在函数间传递切片和映射的高效方式
1. 数组——固定长度的连续内存块
在Go语言中,数组是一个长度固定的数据类型,用于存储一段具有相同类型的连续元素。数组的类型包括元素类型和长度,例如[5]int和[10]int是不同的类型。
1.1 内部实现

图1:数组的内部实现
数组在内存中是一段连续的块。由于内存连续,CPU可以缓存更久的数据,索引计算也极其快速。每个元素可以通过唯一的索引(下标)访问。
1.2 声明和初始化
声明数组时必须指定元素类型和长度:
var array [5]int // 所有元素初始化为int的零值0
图2:声明数组变量后数组的值
可以使用数组字面量快速初始化:
// 指定所有元素的值
array := [5]int{10, 20, 30, 40, 50}
// 让编译器自动计算长度
array := [...]int{10, 20, 30, 40, 50}
// 指定索引赋值,其他保持零值
array := [5]int{1: 10, 2: 20}
图3:声明之后数组的值
1.3 使用数组
通过[]操作符访问和修改元素:
array := [5]int{10, 20, 30, 40, 50}
array[2] = 35
图4:修改索引为2的值之后数组的值
数组的元素可以是任何类型,包括指针:
// 指针数组
array := [5]*int{0: new(int), 1: new(int)}
*array[0] = 10
*array[1] = 20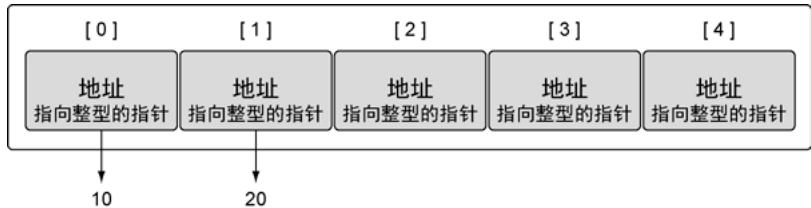
图5:指向整数的指针数组
数组是值类型:数组变量代表整个数组,赋值时会复制所有元素。
var array1 [5]string
array2 := [5]string{"Red", "Blue", "Green", "Yellow", "Pink"}
array1 = array2 // 复制所有元素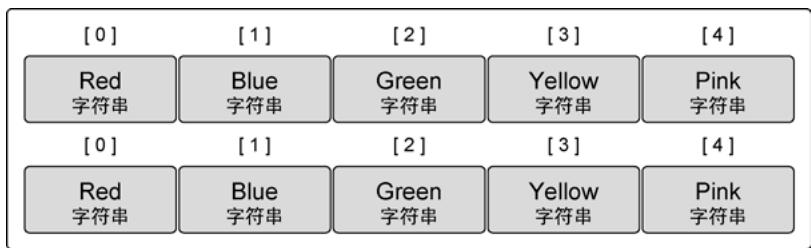
图6:复制之后的两个数组
只有类型(长度+元素类型)完全相同的数组才能互相赋值。以下代码会编译错误:
var array1 [4]string
array2 := [5]string{"Red", "Blue", "Green", "Yellow", "Pink"}
array1 = array2 // 编译错误:类型不匹配复制指针数组时,复制的是指针值(地址),不会复制指向的数据:
var array1 [3]*string
array2 := [3]*string{new(string), new(string), new(string)}
*array2[0] = "Red"
*array2[1] = "Blue"
*array2[2] = "Green"
array1 = array2 // 两个数组共享同一组字符串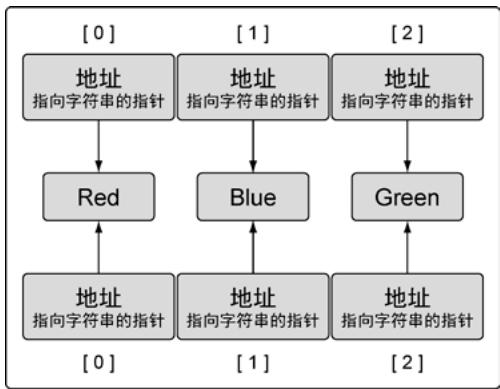
图7:两组指向同样字符串的数组
1.4 多维数组
通过组合多个数组可以创建多维数组:
var array [4][2]int
array := [4][2]int{{10, 11}, {20, 21}, {30, 31}, {40, 41}}
array := [4][2]int{1: {20, 21}, 3: {40, 41}}
array := [4][2]int{1: {0: 20}, 3: {1: 41}}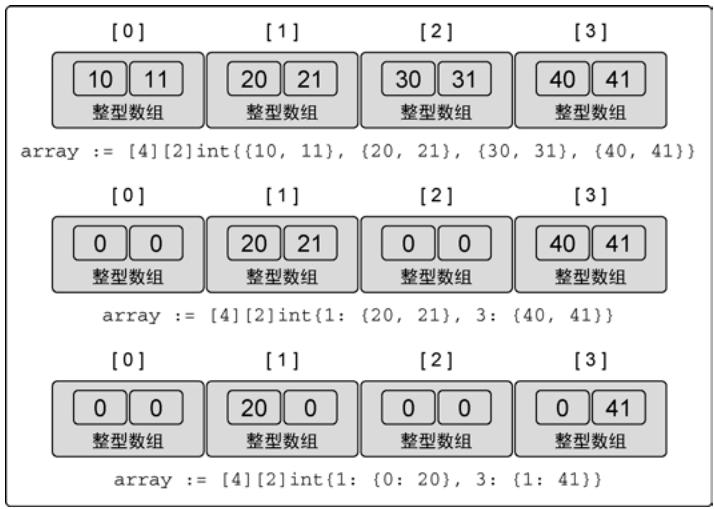
图8:二维数组及其外层数组和内层数组的值
访问元素时使用多个[]:
var array [2][2]int
array[0][0] = 10
array[0][1] = 20
array[1][0] = 30
array[1][1] = 40多维数组也可以赋值,只要类型完全一致:
var array1 [2][2]int
array2 := [2][2]int{{10,20},{30,40}}
array1 = array2 // 复制整个二维数组1.5 在函数间传递数组
由于数组是值类型,直接传递数组会复制整个数组,开销巨大。例如一个100万int的数组(8MB):
var array [1e6]int
foo(array) // 复制8MB到栈上
func foo(array [1e6]int) {
// ...
}更高效的方式是传递指针,只需复制8字节的地址:
foo(&array) // 只复制指针
func foo(array *[1e6]int) {
// ...
}但传递指针意味着函数内对数组的修改会影响到原数组。使用切片可以更好地处理这类需求。
模块小结:数组是固定长度、连续内存、值类型的数据结构。适用于长度固定且需要高性能的场景,但复制成本高,通常用切片替代。
2. 切片——动态数组的抽象
切片是一种轻量级数据结构,围绕动态数组构建,可以按需自动增长和缩小。
2.1 内部实现
切片包含三个字段(共24字节):
- 指针:指向底层数组的起始位置
- 长度:当前切片包含的元素个数
- 容量:从指针位置到底层数组末尾的元素个数
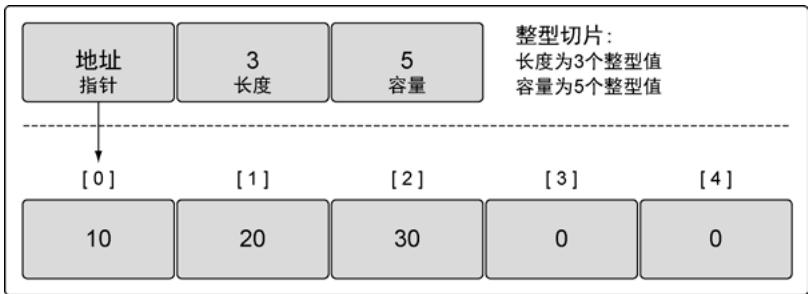
图9:切片内部实现:底层数组
2.2 创建和初始化
使用make创建
// 长度和容量均为5
slice := make([]string, 5)
// 长度3,容量5
slice := make([]int, 3, 5)注意:容量不能小于长度,否则编译错误。
使用切片字面量
// 长度和容量均为5
slice := []string{"Red", "Blue", "Green", "Yellow", "Pink"}
// 长度和容量均为3
slice := []int{10, 20, 30}
// 指定索引创建,长度100,容量100,第100个元素初始化为空字符串
slice := []string{99: ""}区分数组和切片:[]内没有数字是切片,有数字是数组。
array := [3]int{10, 20, 30} // 数组
slice := []int{10, 20, 30} // 切片nil切片和空切片
声明但不初始化得到nil切片:
var slice []int // nil切片
图10:nil切片的表示
使用make或字面量创建空切片:
slice := make([]int, 0) // 空切片
slice := []int{} // 空切片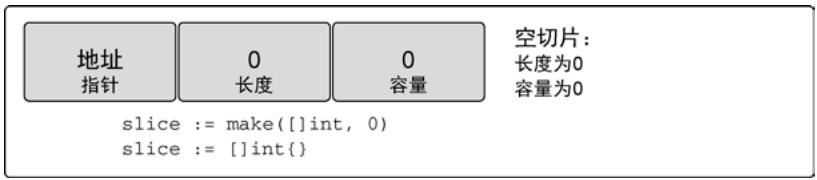
图11:空切片的表示
nil切片和空切片在调用append、len、cap时效果相同。
2.3 使用切片
赋值和切片操作
通过索引修改元素:
slice := []int{10, 20, 30, 40, 50}
slice[1] = 25通过切片操作创建新切片(共享底层数组):
slice := []int{10, 20, 30, 40, 50}
newSlice := slice[1:3] // 长度2,容量4(从索引1到末尾共4个元素)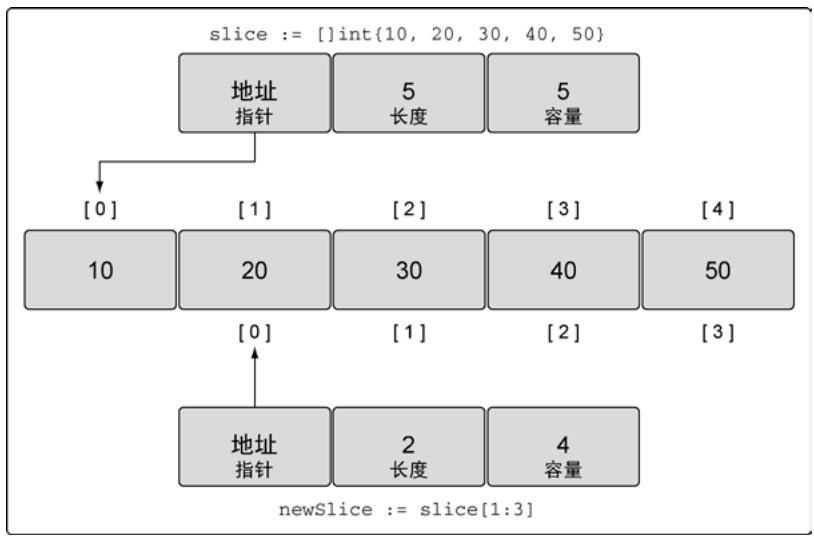
图12:共享同一底层数组的两个切片
计算长度和容量:
- 长度 =
j - i - 容量 =
k - i(k为底层数组容量,未指定时默认为底层数组容量)
// 对底层数组容量为5的slice[1:3]
长度 = 3-1 = 2
容量 = 5-1 = 4修改新切片会反映到原切片:
newSlice[1] = 35 // 同时修改了slice[2]的值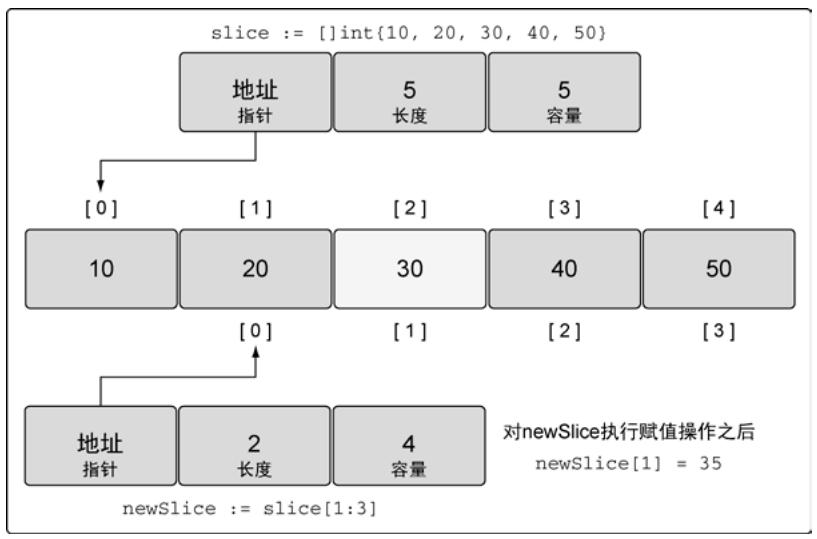
图13:赋值操作之后的底层数组(图中的30要被35替换)
注意:不能访问超出长度的元素,即使容量足够,否则引发panic。
newSlice[3] = 45 // panic: index out of range切片增长:append
使用append向切片追加元素。如果容量足够,直接使用剩余容量;如果容量不足,创建新的底层数组,容量按一定策略增长(小于1000时翻倍,之后增长因子1.25)。
容量足够时:
slice := []int{10, 20, 30, 40, 50}
newSlice := slice[1:3] // [20,30], 容量4
newSlice = append(newSlice, 60) // 使用原底层数组的剩余容量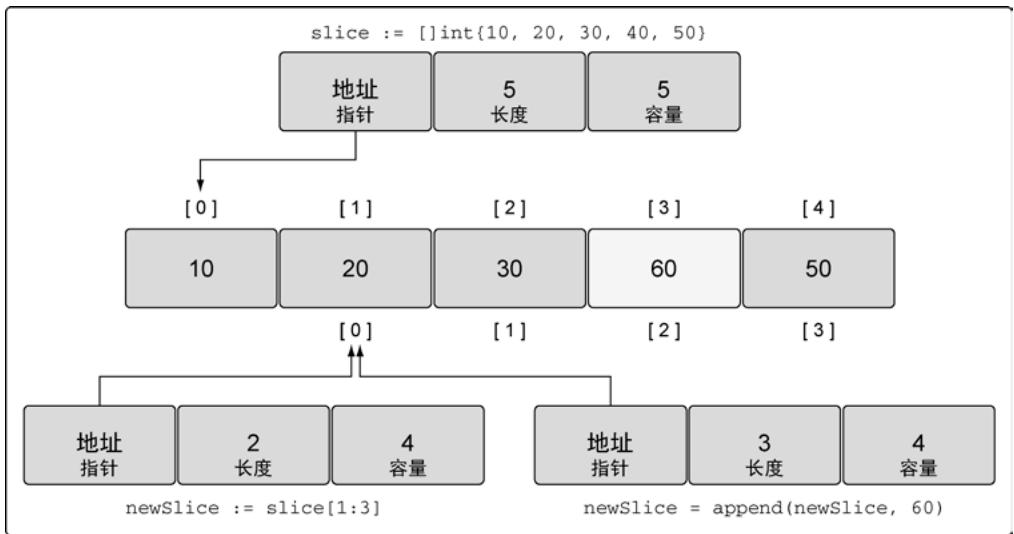
图14:append操作之后的底层数组
容量不足时:
slice := []int{10, 20, 30, 40}
newSlice := append(slice, 50) // 创建新底层数组,容量加倍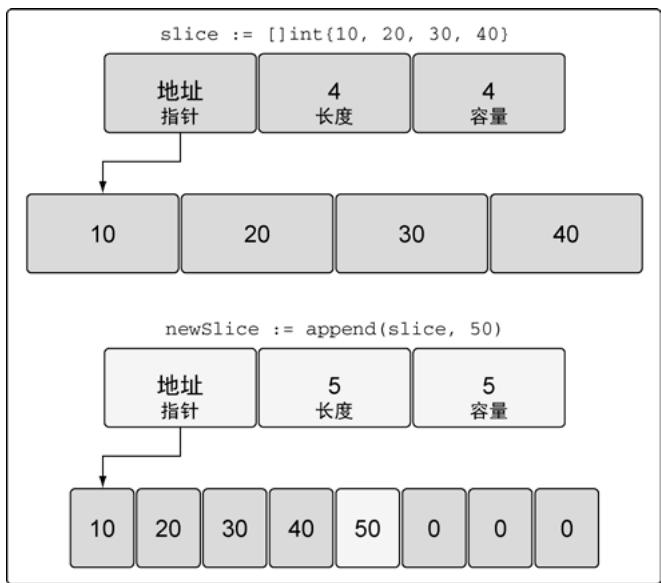
图15:append操作之后的新的底层数组
创建切片时的三个索引
使用[i:j:k]语法可以同时控制新切片的长度和容量,限制容量可避免意外修改共享的底层数组。
source := []string{"Apple", "Orange", "Plum", "Banana", "Grape"}
slice := source[2:3:4] // 长度1,容量2(从索引2到索引3,不含4)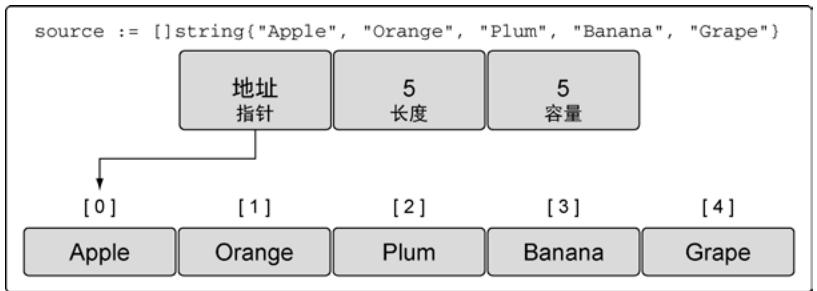
图16:字符串切片的表示
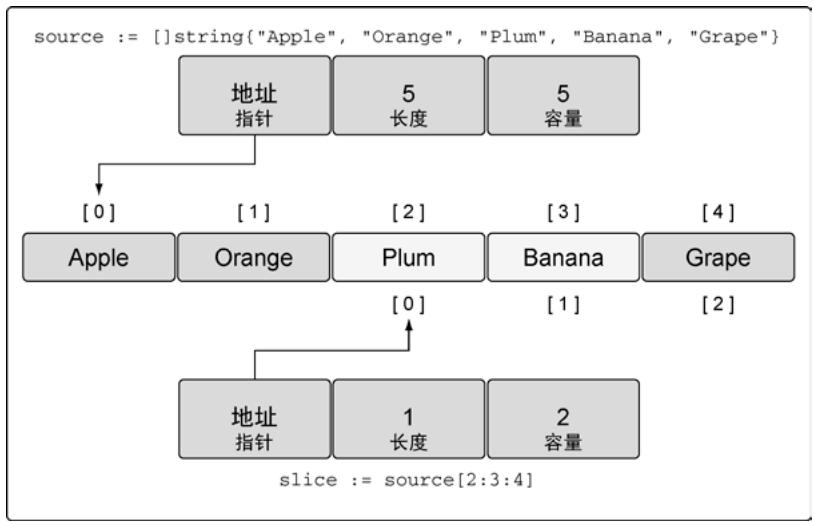
图17:操作之后的新切片的表示
长度 = j-i,容量 = k-i。如果k超过底层数组容量,引发panic。
限制容量的好处:当长度等于容量时,第一次append就会创建新底层数组,与原数组分离,避免意外修改。
slice := source[2:3:3] // 长度1,容量1
slice = append(slice, "Kiwi") // 创建新数组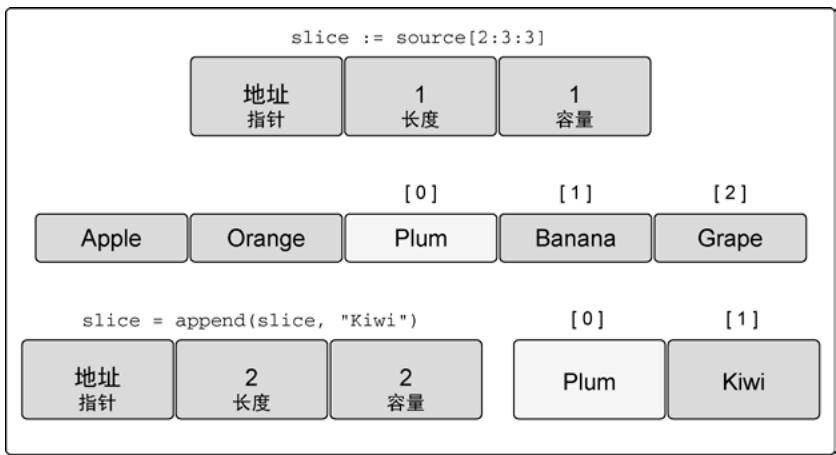
图18:append操作之后的新切片的表示
追加多个元素:
s1 := []int{1, 2}
s2 := []int{3, 4}
result := append(s1, s2...) // [1,2,3,4]迭代切片
使用for range迭代切片:
slice := []int{10, 20, 30, 40}
for index, value := range slice {
fmt.Printf("Index: %d Value: %d\n", index, value)
}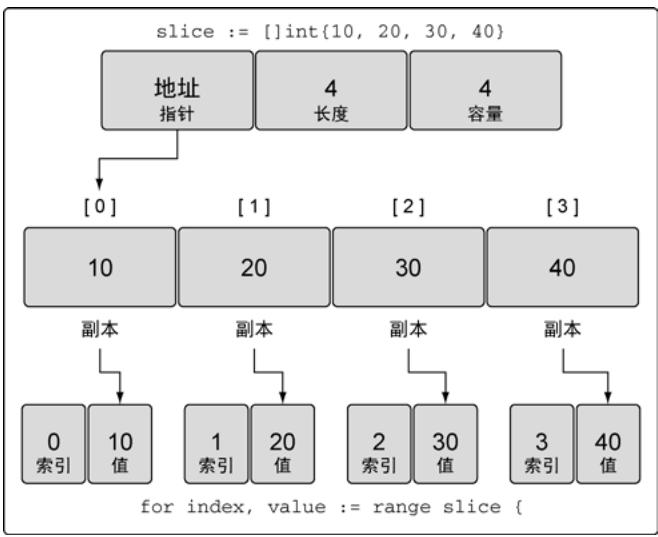
图19:使用range迭代切片会创建每个元素的副本
重要:value是元素的副本,其地址始终相同。要获取元素地址,应使用&slice[index]。
for index, value := range slice {
fmt.Printf("Value: %d Value-Addr: %p ElemAddr: %p\n",
value, &value, &slice[index])
}
// Value-Addr每次相同,ElemAddr每次不同忽略索引使用下划线:
for _, value := range slice {
fmt.Println(value)
}也可以使用传统for循环:
for index := 2; index < len(slice); index++ {
fmt.Println(slice[index])
}2.4 多维切片
切片可以组合成多维结构:
slice := [][]int{{10}, {100, 200}}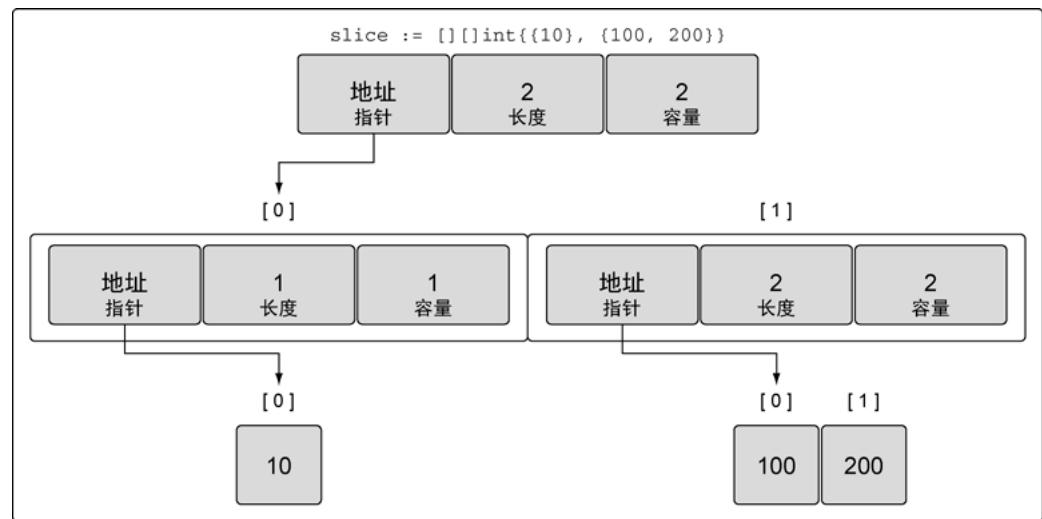
图20:整型切片的切片的值
对内部切片操作同样适用:
slice[0] = append(slice[0], 20)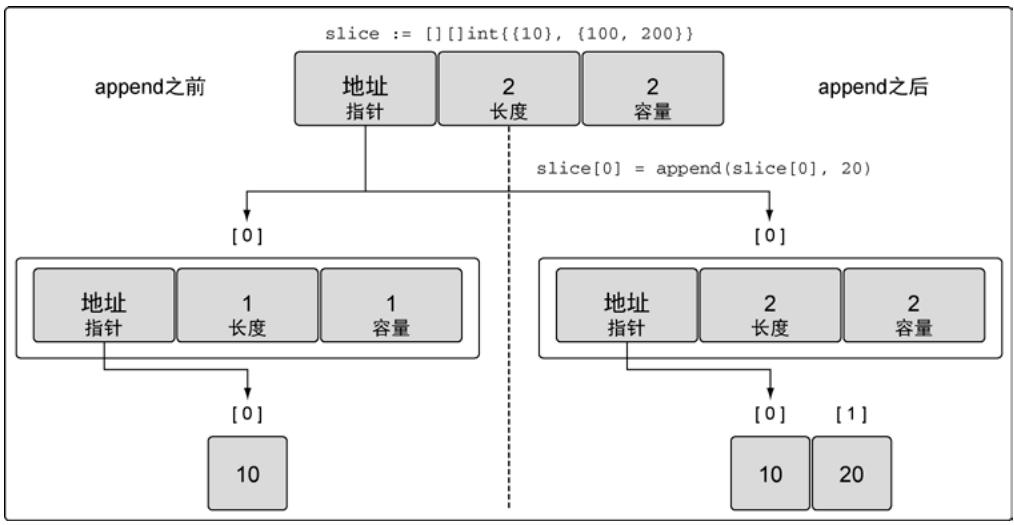
图21:append操作之后外层切片索引为0的元素的布局
2.5 在函数间传递切片
切片本身只占24字节,传递切片只是复制这24字节的数据,底层数组不复制,因此效率高。
slice := make([]int, 1e6)
foo(slice) // 只复制24字节
func foo(slice []int) []int {
return slice
}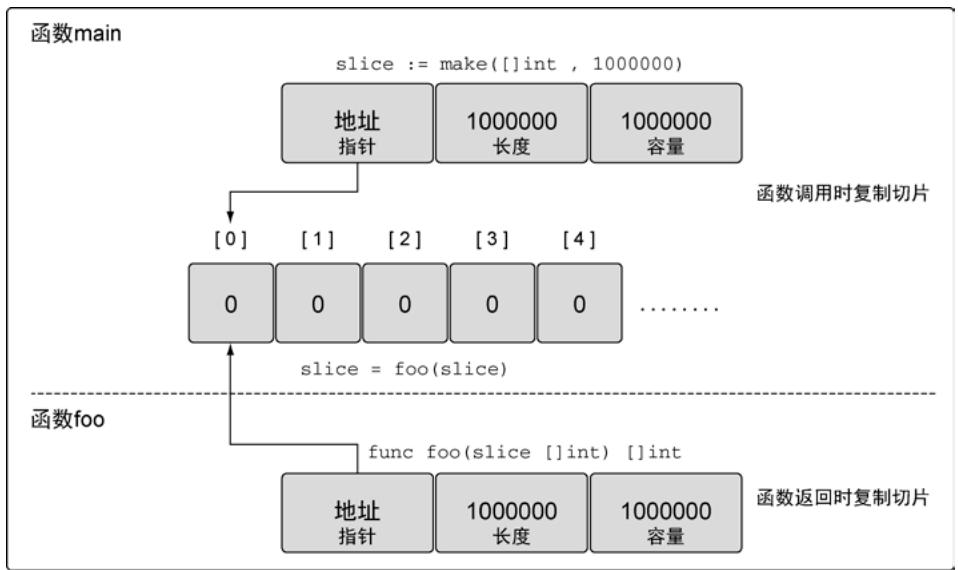
图22:函数调用之后两个切片指向同一个底层数组
模块小结:切片是Go语言处理集合的首选。它基于数组,提供动态扩容,通过
append增长,通过切片操作共享底层数组。理解容量和三个索引能避免常见的共享陷阱。
3. 映射——无序键值对集合
映射(map)用于存储键值对,基于哈希表实现,提供快速的键查找。
3.1 内部实现

图23:键值对的关系
映射的底层是一个哈希表,包含多个桶。当键值对数量增加时,桶的数量也会增加,以保持均匀分布。
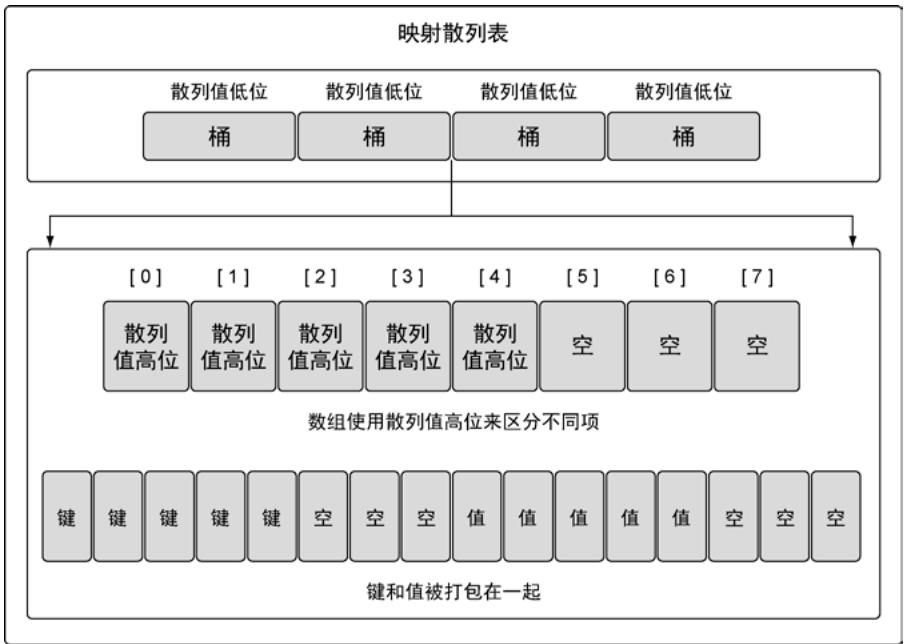
图24:映射的内部结构的简单表示
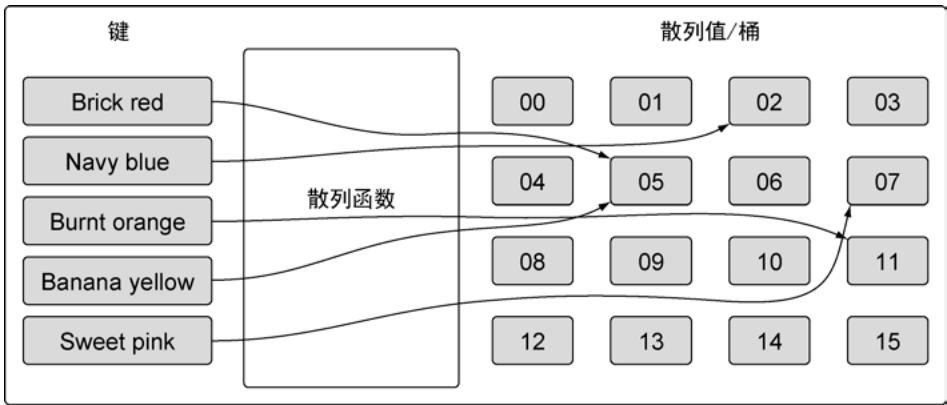
图25:简单描述散列函数是如何工作的
3.2 创建和初始化
使用make创建:
dict := make(map[string]int)使用字面量创建并初始化:
dict := map[string]string{"Red": "#da1337", "Orange": "#e95a22"}键的限制:键必须支持==比较。切片、函数以及包含切片的类型不能作为键,否则编译错误。
// 错误示例
dict := map[[]string]int{} // 编译错误但切片可以作为值:
dict := map[int][]string{} // 正确3.3 使用映射
赋值:
colors := map[string]string{}
colors["Red"] = "#da1337"nil映射:声明但未初始化(nil映射)不能赋值,否则panic。
var colors map[string]string // nil映射
colors["Red"] = "#da1337" // panic检查键是否存在:
value, exists := colors["Blue"]
if exists {
fmt.Println(value)
}或者仅取值,通过零值判断(注意:如果值的零值有实际含义,则需谨慎):
value := colors["Blue"]
if value != "" {
fmt.Println(value)
}迭代映射:使用for range,每次返回键和值,顺序不确定。
colors := map[string]string{
"AliceBlue": "#f0f8ff",
"Coral": "#ff7F50",
"DarkGray": "#a9a9a9",
"ForestGreen": "#228b22",
}
for key, value := range colors {
fmt.Printf("Key: %s Value: %s\n", key, value)
}删除键值对:使用delete函数。
delete(colors, "Coral")3.4 在函数间传递映射
映射是引用类型,传递时只复制引用(指针),因此函数内对映射的修改会影响原映射。
func main() {
colors := map[string]string{
"AliceBlue": "#f0f8ff",
"Coral": "#ff7F50",
}
removeColor(colors, "Coral")
// colors中已无Coral
}
func removeColor(colors map[string]string, key string) {
delete(colors, key)
}模块小结:映射是哈希表实现的无序键值对集合,支持快速查找。键必须可比较,传递开销小。适用于缓存、配置、计数等场景。
4. 本篇核心知识点速记
- 数组:固定长度、连续内存、值类型。声明
[n]T,初始化可指定索引,赋值复制所有元素。传递大数组推荐用指针。 - 切片:动态数组,包含指针、长度、容量。创建用
make([]T, len, cap)或字面量[]T{...}。操作[i:j]生成新切片共享底层数组;[i:j:k]限制容量。append增长切片,容量不足时自动扩容。切片传递仅复制24字节,高效。 - 映射:哈希表实现的无序键值对,创建用
make(map[K]V)或字面量map[K]V{...}。键必须可比较(不能是切片、函数)。检查存在用v, ok := m[k]。删除用delete(m, k)。传递映射仅复制引用。
文末小结
本篇我们深入剖析了Go语言的核心数据结构。数组作为基础,提供了连续内存的高性能存储;切片在其之上构建了动态、灵活的集合管理;映射则通过哈希表实现了高效的键值对查找。理解这些结构的内部实现(特别是切片的容量与共享机制)是写出高效、安全Go代码的关键。
配套检测题
一、选择题
1. 关于数组和切片的区别,以下说法正确的是:
A. 数组和切片声明时都使用[]
B. 数组长度固定,切片长度可变
C. 切片不能作为函数的返回值
D. 数组是引用类型
2. 切片的内部结构包含哪些字段?
A. 指针、长度、容量
B. 起始位置、结束位置、容量
C. 地址、长度、偏移量
D. 基地址、当前元素数、最大元素数
3. 关于切片操作s := slice[1:3:4],以下说法正确的是:
A. 长度为3,容量为4
B. 长度为2,容量为3
C. 长度为2,容量为4
D. 长度为3,容量为2
4. 关于切片的append操作,以下说法错误的是:
A. 当容量足够时,直接使用剩余容量
B. 当容量不足时,创建新的底层数组
C. append不会影响原切片
D. append永远不会创建新数组
5. 关于映射的键的限制,说法正确的是:
A. 任何类型都可以作为映射的键
B. 切片可以作为映射的键
C. 映射的键必须支持==比较
D. 字符串不能作为映射的键
二、填空题
6. 数组是________(值/引用)类型,赋值时会复制所有元素。
7. 切片传递到函数时,只复制________字节的数据。
8. 映射是基于________实现的,提供快速的键查找。
9. 切片容量增长策略:小于1000时________,之后增长因子________。
10. 检查映射键是否存在时,使用v, ok := m[k],如果ok为true表示________。
三、问答题
11. 解释为什么大数组直接传递到函数里会很低效,以及如何解决。
12. 说明切片的三个索引[i:j:k]的含义及其作用。
13. 解释为什么切片操作生成的新切片共享底层数组可能导致的问题,以及如何避免。
14. 说明nil切片和空切片的区别,以及它们的适用场景。
四、编程题
15. 编写代码演示数组和切片的区别:
// 1. 声明一个长度为5的数组和一个长度5的切片
// 2. 修改切片的元素,观察是否影响原数组
// 3. 编写函数,接收切片参数,打印并尝试修改
// 4. 演示值类型vs引用类型的区别16. 编写代码演示切片的扩容机制:
// 1. 创建一个容量为2、长度为0的切片
// 2. 使用append添加5个元素,每次打印长度和容量
// 3. 观察容量变化的时机
// 4. 使用三个索引创建切片,限制容量17. 编写代码演示映射的用法:
// 1. 创建一个映射存储用户信息(用户名->邮箱)
// 2. 添加、修改、删除用户
// 3. 检查用户是否存在
// 4. 使用for range遍历映射
// 5. 说明为什么映射的遍历顺序不确定五、综合应用题
18. 实现一个简化的任务队列:
// 1. 使用切片模拟队列(FIFO)
// 2. 实现Enqueue添加任务
// 3. 实现Dequeue取出任务
// 4. 队列为空时Dequeue返回空字符串
// 5. 说明为什么切片适合实现队列19. 分析以下代码的输出结果并解释原因:
package main
import "fmt"
func main() {
slice := []int{10, 20, 30, 40, 50}
newSlice := slice[1:3]
fmt.Printf("Original slice: %v\n", slice)
fmt.Printf("New slice: %v\n", newSlice)
fmt.Printf("New slice length: %d, capacity: %d\n", len(newSlice), cap(newSlice))
newSlice = append(newSlice, 60)
fmt.Printf("After append - Original slice: %v\n", slice)
fmt.Printf("After append - New slice: %v\n", newSlice)
newSlice[1] = 35
fmt.Printf("After modify - Original slice: %v\n", slice)
fmt.Printf("After modify - New slice: %v\n", newSlice)
}答案
一、选择题答案
1. B 数组声明使用[n]T,切片声明使用[]T(无长度)。切片长度可变,数组长度固定。
2. A 切片包含三个字段:指针(指向底层数组)、长度(当前元素数)、容量(从指针位置到底层数组末尾的元素数)。
3. C slice[1:3:4]创建新切片,起始索引1,结束索引3(不含),容量到索引4。长度=j-i=2,容量=k-i=3,但受限于原容量,所以实际是2。
4. D 当容量不足时,append会创建新的底层数组(翻倍策略),原数组的数据会被复制到新数组。
5. C 映射的键必须支持==比较。切片、函数、包含切片的类型不能作为键,因为它们不支持==比较。
二、填空题答案
6. 值
7. 24
8. 哈希表
9. 翻倍(2倍);1.25
10. 键存在
三、问答题答案
11. 数组是值类型,直接传递会复制整个数组。如果数组很大(如100万个int,需要复制8MB),会消耗大量栈空间和CPU时间。解决方案:1)传递指针(但需注意修改会影响原数组);2)使用切片代替数组(切片只复制24字节的header)。
12. slice[1:3:4]三个索引含义:
i:起始索引,新切片从原切片的这个位置开始j:结束索引,新切片到这个位置(不含)k:容量索引,新切片的容量设为k-i
作用:限制新切片的容量,避免意外修改共享的底层数组。当长度等于容量时,第一次append就会创建新底层数组,与原数组分离。
13. 问题:当两个切片共享底层数组时,对一个切片的修改会影响另一个切片。例如:
s1 := []int{1,2,3,4,5}
s2 := s1[1:3]
s2[0] = 10 // 同时修改了s1[1]避免方法:使用三个索引[i:j:k]限制容量,当append新元素时如果容量不足,会创建新数组:
s2 := s1[1:3:3] // 容量=1
s2 = append(s2, 6) // 创建新数组,s1不受影响14. nil切片:var s []int,未初始化,指针为nil。 空切片:s := []int{}或s := make([]int, 0),已初始化,指针指向一个空数组。
区别:两者在调用append、len、cap时效果相同,但序列化时nil切片输出为[],空切片输出为[]。
适用场景:nil切片通常用于表示"不存在或未知",如函数返回失败时;空切片用于表示"存在但为空",如空结果集。
四、编程题答案
15.
package main
import "fmt"
func modifySlice(s []int) {
s[0] = 100
}
func main() {
// 数组
arr := [5]int{1, 2, 3, 4, 5}
arr2 := arr // 复制整个数组
arr2[0] = 99
fmt.Println(arr, arr2) // [1 2 3 4 5] [99 2 3 4 5]
// 切片
slice := []int{1, 2, 3, 4, 5}
slice2 := slice // 复制切片header(指针+长度+容量),共享底层数组
slice2[0] = 99
fmt.Println(slice, slice2) // [99 2 3 4 5] [99 2 3 4 5]
// 函数参数
modifySlice(slice)
fmt.Println(slice) // [100 2 3 4 5],修改了原切片
}16.
package main
import "fmt"
func main() {
slice := make([]int, 0, 2)
fmt.Printf("Initial - Len: %d, Cap: %d\n", len(slice), cap(slice))
for i := 1; i <= 5; i++ {
slice = append(slice, i)
fmt.Printf("After append %d - Len: %d, Cap: %d\n", i, len(slice), cap(slice))
}
// 使用三个索引限制容量
source := []int{1, 2, 3, 4, 5}
limited := source[0:2:2]
fmt.Printf("Limited slice: %v, Len: %d, Cap: %d\n", limited, len(limited), cap(limited))
limited = append(limited, 99)
fmt.Printf("After append: %v, source: %v\n", limited, source)
}17.
package main
import "fmt"
func main() {
users := make(map[string]string)
users["Alice"] = "alice@email.com"
users["Bob"] = "bob@email.com"
// 修改
users["Alice"] = "new.alice@email.com"
// 检查存在
if email, ok := users["Charlie"]; ok {
fmt.Println("Charlie:", email)
} else {
fmt.Println("Charlie not found")
}
// 删除
delete(users, "Bob")
// 遍历(顺序不确定)
for name, email := range users {
fmt.Printf("%s: %s\n", name, email)
}
}为什么遍历顺序不确定:映射基于哈希表实现,哈希函数会计算出键的存储位置。为了保持高效的查找性能,Go不保证映射的遍历顺序,每次遍历可能不同。如果需要有序遍历,可以将键提取到切片中排序后再遍历。
五、综合应用题答案
18.
package main
import "fmt"
type Queue struct {
items []string
}
func (q *Queue) Enqueue(item string) {
q.items = append(q.items, item)
}
func (q *Queue) Dequeue() string {
if len(q.items) == 0 {
return ""
}
item := q.items[0]
q.items = q.items[1:]
return item
}
func main() {
q := &Queue{}
q.Enqueue("task1")
q.Enqueue("task2")
q.Enqueue("task3")
fmt.Println(q.Dequeue()) // task1
fmt.Println(q.Dequeue()) // task2
fmt.Println(q.Dequeue()) // task3
fmt.Println(q.Dequeue()) // ""
q.Enqueue("task4")
fmt.Println(q.Dequeue()) // task4
}为什么切片适合实现队列:切片的append可以在末尾高效添加元素(均摊O(1)),切片的索引访问可以高效从头部取出元素。但出队操作items = items[1:]会创建新的底层数组切片,如果队列很大可能有性能问题。生产环境中更推荐使用container/list或环形缓冲区。
19. 输出结果:
Original slice: [10 20 30 40 50]
New slice: [20 30]
New slice length: 2, capacity: 4
After append - Original slice: [10 20 60 40 50]
After append - New slice: [20 60 60]
After modify - Original slice: [10 20 35 40 50]
After modify - New slice: [20 35 60]解释:
newSlice := slice[1:3]创建新切片,指向同一个底层数组[10,20,30,40,50]newSlice长度2,容量4(从索引1到底层数组末尾共4个元素)append(newSlice, 60)时容量足够,直接使用剩余容量,在索引2(=原数组索引3)写入60,同时newSlice长度变为3- 再次
newSlice[1] = 35修改的是原数组索引2,所以原数组变为[10,20,35,40,50]
核心问题:切片共享底层数组,一个切片的修改可能影响另一个切片。使用三个索引限制容量可以避免这个问题。