18 JDK8_17新特性
Java版本迭代概述
发布特点
小步快跑,快速迭代
| 发行版本 | 发行时间 | 备注 |
|---|---|---|
| Java1.0 | 1996.01.23 | Sun公司发布了Java的第一个开发工具包 |
| Java5.0 | 2004.09.30 | ①版本号从1.4直接更新至5.0 ②平台更名为JavaSE、JavaEE、JavaME |
| Java8.0 | 2014.03.18 | 此版本是,是长期支持版本LTS |
| Java9.0 | 2017.09.22 | 此版本开始,每半年更新一次 |
| Java10.0 | 2018.03.21 | |
| Java11.0 | 2018.09.25 | ,是长期支持版本LTS |
| Java12.0 | 2019.03.19 | |
| ... | ... | |
| Java17.0 | 2021.09 | 发布Java17.0,版本号也称为21.9,是长期支持版本LTS |
| ... | ... | |
| Java19.0 | 2022.09 | 发布Java19.0,版本号也称为22.9 |
从Java9这个版本开始,Java的计划发布周期是6个月,Java的更新 ,并且承诺不会跳票。通过这样的方式,开发团队可以把一些关键特性尽早合并到JDK之中,以快速得到开发者反馈,在一定程度上避免出现像Java9两次被迫延迟发布的窘况。
针对企业客户的需求,Oracle将以三年为周期发布长期支持版本LongTermSupport。
Oracle官方观点认为:与Java7->8->9相比,Java9->10->11的升级和8->8u20->8u40更相似。
新模式下的Java版本发布都会包含许多变更,包括:语言变更、JVM变更,这两者都会对IDE、字节码库、框架产生重大影响。此外,不仅会新增其他API,还会有API被删除(Java8)。
Java/JVM演进的许多枷锁,至关重要的是,OpenJDK的权力中心正在转移到开发社区和开发者手中。在新的模式中,即可以利用LTS满足企业长期可靠支持的需求,又可以满足各种开发者对于新特性迭代的诉求。因为用2~3年的最小间隔粒度来试验一个特性,基本是不现实的。名词解释
OracleJDK和OpenJDK
这两个JDK最大不同就是 ,但是对于个人用户来讲没区别。
| OracleJDK | OpenJDK | |
|---|---|---|
| 来源 | ||
| 授权协议 | Java17及更高版本:Oracle Java SE许可证 Java16及更低版本:甲骨文免费条款和条件(No-Fee Terms and Conditions,NFTC)许可协议 | GPLv2许可证 |
| 关系 | 由OpenJDK构建,增加了少许内容 | |
| 是否收费 | 20219Java17,16及更低版本:个人用户、开发用户免费 | 2017年9月起,所有版本免费 |
| 对语法的支持 | 一致 | 一致 |
JEP
JEP(JDK Enhancement Proposals):jdk,每当需要有新的设想时候,JEP可以提出非正式的规范(specification),被正式认可的JEP正式写进JDK的发展路线图并分配版本号。
LTS
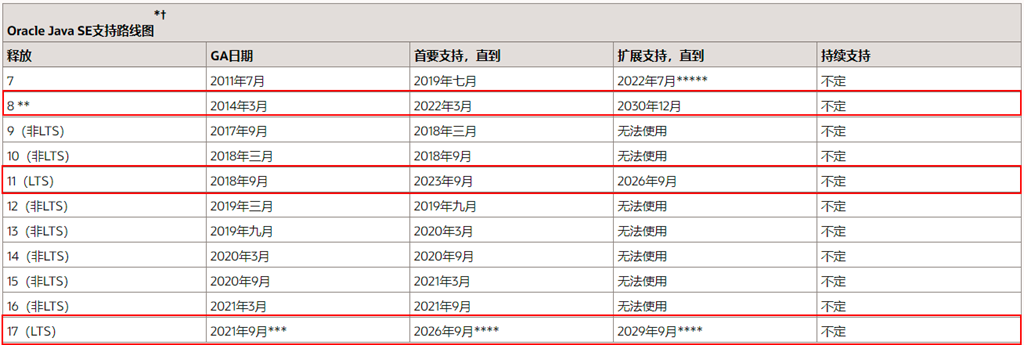
LTS(Long-term Support)即:长期支持,Oracle官网提供了对OracleJDK个别版本的长期支持,JDK19LTS版本都会被长期支持,(出了bug会被修复,非LTS)所以,一定要选一个LTS版本,不然出了漏洞没人修复了。
| 版本 | 开始日期 | 结束日期 | 延期结束日期 |
|---|---|---|---|
| 7(LTS) | 2011年7月 | 2019年7月 | 2022年7月 |
| 8(LTS) | 2014年3月 | 2022年3月 | 2030年12月 |
| 11(LTS) | 2018年9月 | 2023年9月 | 2026年9月 |
| 17(LTS) | 2021年9月 | 2026年9月 | 2029年9月 |
| 21(LTS) | 2023年9月 | 2028年9月 | 2031年9月 |
如果要选择OracleJDK,可选LTS版本8、11、17等几个。
各版本支持时间路线图
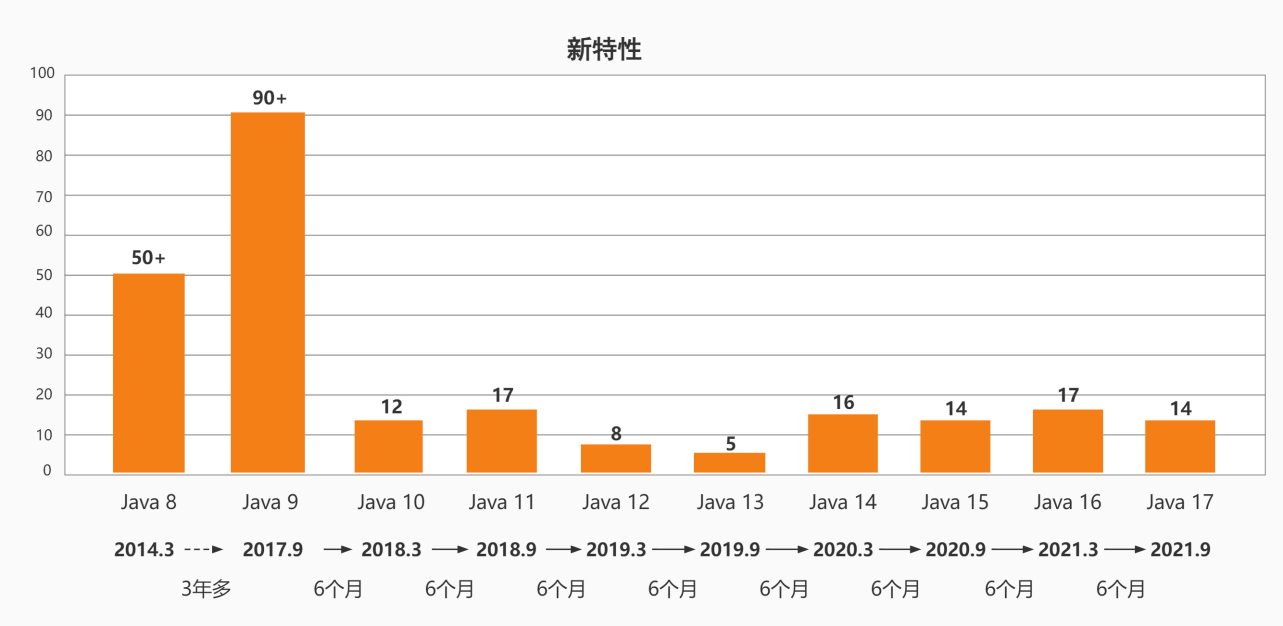
各版本介绍
- JDK9
- https://openjdk.java.net/projects/jdk9/(特性较多,参考官方文档)
- JDK10
- https://openjdk.java.net/projects/jdk/10/
- 286:局部变量类型推断
- 296:JDK库的合并
- 304:统一的垃圾回收接口
- 307:为G1提供并行的FullGC
- 312:ThreadLocal握手交互
- 313:移除JDK中附带的javah工具
- 314:使用附加的Unicode语言标记扩展
- 316:能将堆内存占用分配给用户指定的备用内存设备
- 317:使用Graal基于Java的编译器
- https://openjdk.java.net/projects/jdk/10/
- JDK11
- https://openjdk.java.net/projects/jdk/11/
- 181:基于嵌套的访问控制
- 309:动态类文件常量
- 320:删除JavaEE和CORBA模块
- 321:HTTPClientAPI
- 323:用于Lambda参数的局部变量语法
- 331:低开销的HeapProfiling
- 332:支持TLS1.3
- 333:可伸缩低延迟垃圾收集器
- 335:弃用NashornJavaScript引擎
- https://openjdk.java.net/projects/jdk/11/
- JDK12
- https://openjdk.java.net/projects/jdk/12/
- 189:Shenandoah:低暂停时间的GC
- 325:switch表达式
- 334:JVM常量API
- 341:默认类数据共享归档文件
- 344:可中止的G1MixedGC
- 346:G1及时返回未使用的已分配内存
- https://openjdk.java.net/projects/jdk/12/
- JDK13
- https://openjdk.java.net/projects/jdk/13/
- 350:动态CDS档案
- 351:ZGC:取消使用未使用的内存
- 353:重新实现旧版套接字API
- 354:switch表达式(预览)
- 355:文本块(预览)
- https://openjdk.java.net/projects/jdk/13/
- JDK14
- https://openjdk.java.net/projects/jdk/14/
- 305:instanceof的模式匹配
- 358:实用的NullPointerExceptions
- 359:Records(Preview)
- 361:Switch表达式
- 362:弃用Solaris和SPARC端口
- 363:删除并发标记扫描(CMS)垃圾回收器
- 364:ZGC on macOS
- 365:ZGC on Windows
- 368:文本块
- https://openjdk.java.net/projects/jdk/14/
- JDK15
- https://openjdk.java.net/projects/jdk/15/
- 360:密封类(预览)
- 371:隐藏类
- 372:移除Nashorn JavaScript 引擎
- 373:重新实现Legacy DatagramSocket API
- 374:禁用偏向锁定
- 375:instanceof 模式匹配(第二次预览)
- 377:ZGC:一个可扩展的低延迟垃圾收集器
- 378:文本块
- 379:Shenandoah: 低暂停时间垃圾收集器
- 381:移除Solaris 和 SPARC 端口
- 384: Records(第二次预览)
- https://openjdk.java.net/projects/jdk/15/
- JDK16
- https://openjdk.java.net/projects/jdk/16/
- 347:JDK C++的源码中允许使用C++14的语言特性
- 357:OpenJDK源码的版本控制从Mercurial (hg) 迁移到git
- 369:OpenJDK源码的版本控制迁移到github上
- 376:ZGC:并发线程处理
- 386:将glibc的jdk移植到使用musl的alpine linux上
- 387:弹性元空间
- 388:移植JDK到Windows/AArch64
- 389:提供jdk.incubator.foreign来简化native code的调用
- 392:jpackage打包工具转正
- 394:Instanceof的模式匹配转正
- 395:Records转正
- 397:密封类
- https://openjdk.java.net/projects/jdk/16/
- JDK17
- https://openjdk.java.net/projects/jdk/17/
- 356:增强型伪随机数生成器
- 403:强封装JDK的内部API
- 406:switch模式匹配(预览)
- 409:密封类转正
- 410:删除实验性的AOT和JIT编译器
- 415:上下文特定的反序列化过滤器
JDK各版本下载链接
https://www.oracle.com/java/technologies/downloads/archive/
如何学习新特性
对于新特性,应该从哪几个角度学习呢?
- 语法层面:
JDK5中:自动拆箱、自动装箱、enum、泛型JDK8中:lambda表达式、接口中的默认方法、静态方法JDK10中:局部变量的类型推断JDK12中:switchJDK13中:文本块
API层面:JDK8中:Stream、Optional、新的日期时间、HashMap的底层结构JDK9中:String的底层结构- 新的 / 过时的
API
- 底层优化:
JDK8中永久代被元空间替代、新的JS执行引擎- 新的垃圾回收器、
GC参数、JVM的优化
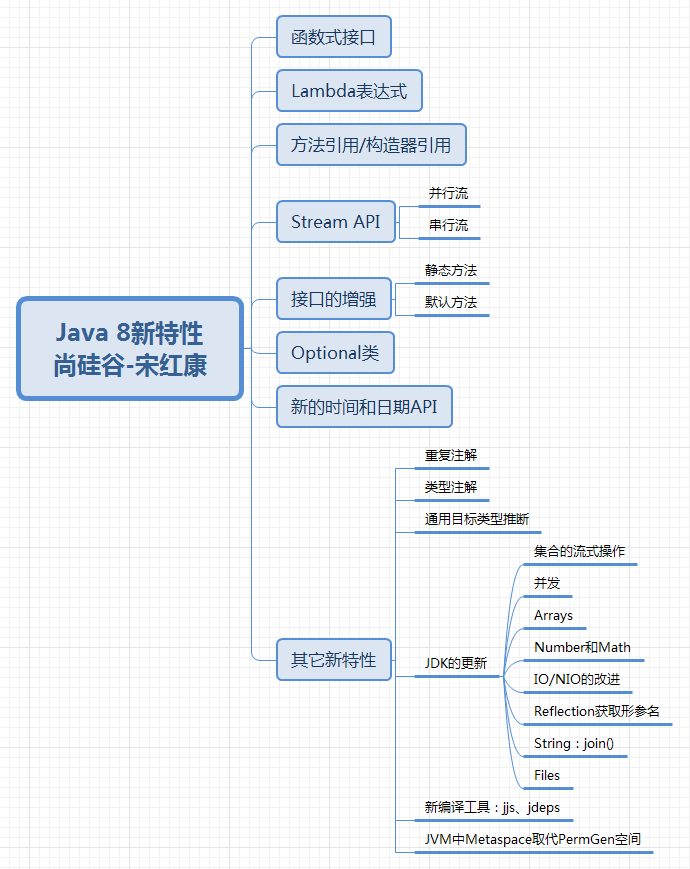
Java8新特性:Lambda表达式
Java8新特性简介
Java8(又称为JDK8或JDK1.8)是Java语言开发的一个主要版本,Java8是oracle公司于2014年3月发布,可以看成是自Java5以来最具革命性的版本,Java8为Java语言、编译器、类库、开发工具与JVM带来了大量新特性。
- 速度更快
- 代码更少(增加了新的语法:
Lambda表达式) - 强大的
Stream API - 便于并行
- 并行流:。相比较串行的流,并行的流可以很大程度上提高程序的执行效率
Java8中将并行进行了优化,可以很容易的对数据进行并行操作。StreamAPIparallel()sequential()
- 最大化减少空指针异常:
Optional Nashorn引擎,允许在JVM上运行JS应用- 发音“
nass-horn”,是德国二战时一个坦克的命名 javascript运行在jvm已经不是新鲜事,Rhino在jdk6的时候已经存在。替代Rhino,官方的解释是Rhino相比其他JavaScript引擎(比如:google的V8)实在太慢了,改造Rhino还不如重写,所以Nashorn的性能也是其一个亮点。Nashorn项目在JDK9中得到改进;在JDK11中Deprecated,后续JDK15版本中remove。在JDK11中取以代之的是GraalVM(GraalVM是一个运行时平台,它支持Java和其他基于Java字节码的语言,但也支持其他语言,如:JavaScript、Ruby、Python或LLVM,性能是Nashorn的2倍以上)
- 发音“
冗余的匿名内部类
当需要启动一个线程去完成任务时,通常会通过java.lang.Runnable接口来定义任务内容,并使用java.lang.Thread类来启动该线程。例如:
public class UseFunctionalProgramming {
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("多线程任务执行...");
}
}).start();
}
}本着“一切皆对象”的思想,这种做法是无可厚非的:首先创建一个Runnable接口的匿名内部类对象来指定任务内容,再将其交给一个线程来启动。
代码分析:
对于Runnable的匿名内部类用法,可以分析出:
Thread类需要Runnable接口作为参数,其中的抽象run方法是用来指定线程任务内容的核心- 为了指定
run的方法体,不得不需要Runnable接口的实现类 - 为了省去定义一个
RunnableImpl实现类的麻烦,不得不使用匿名内部类 - 必须覆盖重写抽象
run方法,所以方法名称、方法参数、方法返回值不得不再写一遍,且不能写错
好用的lambda表达式
Lambda及其使用举例
LambdaLambda,使用它可以写出更简洁、更灵活的代码、作为一种更紧凑的代码风格,提升Java的语言表达能力。
- 从匿名类到
Lambda的转换(举例1)
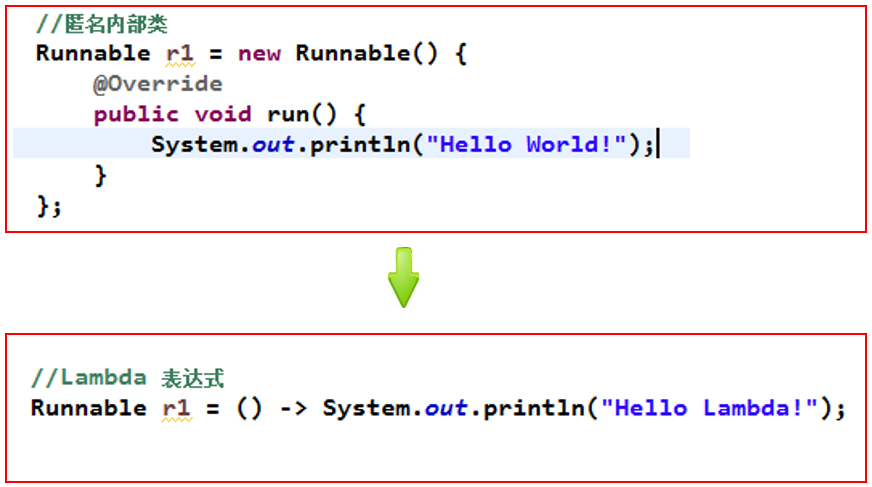
- 从匿名类到
Lambda的转换(举例2)

语法
Lambda表达式:Java8。
操作符为:->,该操作符被称为Lambda操作符或箭头操作符,它将Lambda分为两个部分:
- :指定了
Lambda表达式需要的 - :指定了
Lambda体,是,即:Lambda表达式要执行的功能
语法格式1
public class LambdaExpressionGrammar1 {
public static void main(String[] args) {
// 未使用lambda表达式
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("线程执行1...");
}
};
runnable.run();
// 使用lambda表达式
Runnable runnable2 = () -> {
System.out.println("执行线程2...");
};
runnable2.run();
}
}语法格式2
Lambda1
import java.util.function.Consumer;
public class LambdaExpressionGrammar2 {
public static void main(String[] args) {
// 未使用lambda表达式
Consumer<String> consumer = new Consumer<>() {
@Override
public void accept(String s) {
System.out.println(s);
}
};
consumer.accept("测试字符串1...");
// 使用lambda表达式
Consumer<String> consumer2 = (String s) -> {
System.out.println(s);
};
consumer.accept("测试字符串2...");
}
}语法格式3
- 类型推断
- 关于类型推断
Lambda表达式中的参数类型都是由编译器推断得出的,Lambda表达式中无需指定类型程序依然可以编译,javac。Lambda表达式的类型依赖于上下文环境,是由编译器推断出来的,这就是所谓的类型推断
//类型推断1
ArrayList<String> list = new ArrayList<>();
//类型推断2
int[] arr = {1, 2, 3};- 案例代码(语法格式
3):
import java.util.ArrayList;
import java.util.function.Consumer;
public class LambdaExpressionGrammar3 {
public static void main(String[] args) {
// 未使用语法3
Consumer<String> consumer = (String s) -> {
System.out.println(s);
};
consumer.accept("测试字符串1...");
// 使用语法3
Consumer<String> consumer2 = (s) -> {
System.out.println(s);
};
consumer2.accept("测试字符串2...");
}
}语法格式4
Lambda1
import java.util.function.Consumer;
public class LambdaExpressionGrammar4 {
public static void main(String[] args) {
// 未使用语法4
Consumer<String> consumer = (s) -> {
System.out.println(s);
};
consumer.accept("测试字符串1...");
// 使用语法4
Consumer<String> consumer2 = s -> {
System.out.println(s);
};
consumer2.accept("测试字符串2...");
}
}语法格式5
Lambda2
import java.util.Comparator;
import java.util.function.Consumer;
public class LambdaExpressionGrammar5 {
public static void main(String[] args) {
// 未使用语法5
Comparator<Integer> comparator = new Comparator<>() {
@Override
public int compare(Integer o1, Integer o2) {
System.out.println(o1);
System.out.println(o2);
return o1.compareTo(o2);
}
};
System.out.println(comparator.compare(12, 21));
System.out.println();
// 使用语法5
Comparator<Integer> comparator2 = (o1, o2) -> {
System.out.println(o1);
System.out.println(o2);
return o1.compareTo(o2);
};
System.out.println(comparator2.compare(12, 6));
}
}语法格式6
Lambda1return{}
import java.util.Comparator;
import java.util.function.Consumer;
public class LambdaExpressionGrammar6 {
public static void main(String[] args) {
// 未使用语法6
Comparator<Integer> comparator = (o1, o2) -> {
return o1.compareTo(o2);
};
System.out.println(comparator.compare(12, 6));
System.out.println();
// 使用语法6
Comparator<Integer> comparator2 = (o1, o2) -> o1.compareTo(o2);
System.out.println(comparator.compare(12, 21));
System.out.println("=========================");
// 未使用语法6
Consumer<String> consumer = s -> {
System.out.println(s);
};
consumer.accept("测试字符串1...");
System.out.println();
// 使用语法6
Consumer<String> consumer2 = s -> System.out.println(s);
consumer2.accept("测试字符串2...");
}
}Java8新特性:函数式(Functional)接口
什么是函数式接口
1Single Abstract MethodSAM:函数式接口,- 可以通过
Lambda表达式来创建该接口的对象,Lambda @FunctionalInterfacejavadoc- 在
java.util.function包下定义了Java8的丰富的函数式接口
如何理解

Java从诞生日起就是一直倡导一切皆对象,在Java里面向对象(OOP)编程是一切。但是随着python、scala等语言的兴起和新技术的挑战,Java不得不做出调整以便支持更加广泛的技术要求,即:Java不但可以支持OOP还可以支持OOF面向函数编程Java8引入了Lambda表达式之后,Java也开始支持函数式编程LambdaJava,目前C++、C#、Python、Scala等均支持Lambda表达式
- 面向对象的思想:
- 做一件事情,找一个能解决这个事情的对象,调用对象的方法,完成事情
- 在函数式编程语言当中,函数被当做一等公民对待。
LambdaJava8Java8Lambda - 简单的说,在
Java8中,Lambda表达式就是一个函数式接口的实例,这就是Lambda表达式和函数式接口的关系。Lambda
举例
举例1:

举例2:

作为参数传递Lambda表达式:
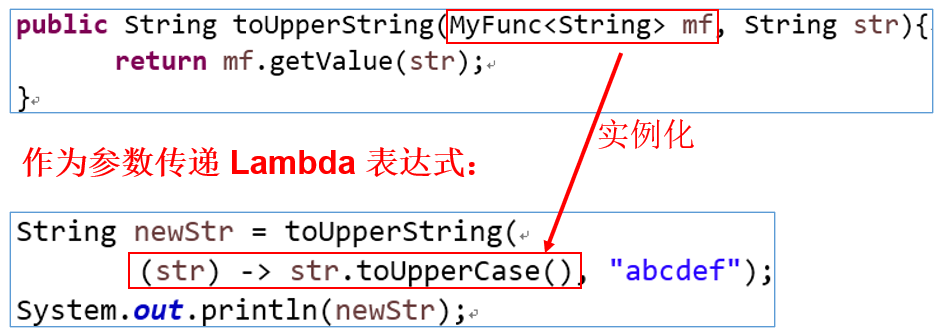
Lambda:为了将Lambda表达式作为参数传递,接收Lambda表达式的参数类型必须是与该Lambda表达式兼容的函数式接口的类型。
Java内置函数式接口
经常使用的函数式接口
java.lang.Runnablepublic void run()
java.lang.Iterablepublic Iterator iterate()
java.lang.Comparablepublic int compareTo(T t)
java.util.Comparatorpublic int compare(T t1, T t2)
四大核心函数式接口
| 函数式接口 | 称谓 | 参数类型 | 用途 |
|---|---|---|---|
Consumer<T> | 消费型接口 | T | 对类型为T的对象应用操作void accept(T t) |
Supplier<T> | 供给型接口 | 无 | 返回类型为T的对象T get() |
Function<T, R> | 函数型接口 | T | 对类型为T的对象应用操作,并返回R类型的结果对象R apply(T t) |
Predicate<T> | 判断型接口 | T | 确定类型为T的对象是否满足某约束,并返回boolean值boolean test(T t) |
使用案例
- Consumer
<T>
import java.util.function.Consumer;
public class ConsumerDemo {
public static void main(String[] args) {
Consumer<String> consumer = new Consumer<>() {
@Override
public void accept(String s) {
System.out.println(s);
}
};
consumer.accept("weew12...");
}
}Supplier<T>
import java.util.function.Supplier;
public class SupplierDemo {
public static void main(String[] args) {
Supplier<String> supplier = new Supplier<>() {
@Override
public String get() {
return "weew12...";
}
};
String s = supplier.get();
System.out.println(s);
}
}Function<T, R>
import java.util.function.Function;
public class FunctionDemo {
public static void main(String[] args) {
Function<String, Integer> function = new Function<>() {
@Override
public Integer apply(String s) {
return s.length();
}
};
Integer apply = function.apply("weew12...");
System.out.println(apply);
}
}Predicate<T>
import java.util.function.Predicate;
public class PredicateDemo {
public static void main(String[] args) {
Predicate<String> predicate = new Predicate<>() {
@Override
public boolean test(String s) {
return s.endsWith(".png");
}
};
boolean test = predicate.test("weew12.png");
System.out.println(test);
}
}其它接口
类型1:消费型接口
void
| 接口名 | 抽象方法 | 描述 |
|---|---|---|
| Bi | void accept(T t, U u) | 接收两个对象用于完成功能 |
| void accept(double value) | 接收一个double值 | |
| void accept(int value) | 接收一个int值 | |
| void accept(long value) | 接收一个long值 | |
ObjDouble Consumer<T> | void accept(T t, double value) | 接收一个对象和一个double值 |
| void accept(T t, int value) | 接收一个对象和一个int值 | |
| void accept(T t, long value) | 接收一个对象和一个long值 |
使用案例:
import java.util.function.BiConsumer;
import java.util.function.DoubleConsumer;
import java.util.function.ObjDoubleConsumer;
public class FunctionInterfaceConsumerType {
public static void main(String[] args) {
// BiConsumer<T,U>
BiConsumer<String, Integer> biConsumer = new BiConsumer<>() {
@Override
public void accept(String s, Integer integer) {
System.out.println(s + integer);
}
};
biConsumer.accept("weew12", 123);
// DoubleConsumer
DoubleConsumer doubleConsumer = new DoubleConsumer() {
@Override
public void accept(double value) {
System.out.println(value);
}
};
doubleConsumer.accept(12.0);
// IntConsumer
// 同上略
// LongConsumer
// 同上略
// ObjDoubleConsumer
ObjDoubleConsumer<String> objDoubleConsumer = new ObjDoubleConsumer<>() {
@Override
public void accept(String s, double value) {
System.out.println(s + value);
}
};
objDoubleConsumer.accept("weew12", 123);
// ObjIntConsumer
// 同上略
// ObjLongConsumer
// 同上略
}
}类型2:供给型接口
| 接口名 | 抽象方法 | 描述 |
|---|---|---|
| boolean getAsBoolean() | 返回一个boolean值 | |
| double getAsDouble() | 返回一个double值 | |
| int getAsInt() | 返回一个int值 | |
| long getAsLong() | 返回一个long值 |
使用案例:
import java.util.function.BooleanSupplier;
import java.util.function.DoubleSupplier;
public class FunctionInterfaceSupplierType {
public static void main(String[] args) {
// BooleanSupplier
BooleanSupplier booleanSupplier = new BooleanSupplier() {
@Override
public boolean getAsBoolean() {
return false;
}
};
boolean asBoolean = booleanSupplier.getAsBoolean();
System.out.println(asBoolean);
// DoubleSupplier
DoubleSupplier doubleSupplier = new DoubleSupplier() {
@Override
public double getAsDouble() {
return 12.0;
}
};
double asDouble = doubleSupplier.getAsDouble();
System.out.println(asDouble);
// IntSupplier
// 同上略
// LongSupplier
// 同上略
}
}类型3:函数型接口
xxxOperator
| 接口名 | 抽象方法 | 描述 |
|---|---|---|
| T apply(T t) | 接收一个T类型对象,返回一个T类型对象结果 | |
| double applyAsDouble(double operand) | 接收一个double值,返回一个double | |
| int applyAsInt(int operand) | 接收一个int值,返回一个int结果 | |
| long applyAsLong(long operand) | 接收一个long值,返回一个long结果 | |
| T apply(T t, T u) | 接收两个T类型对象,返回一个T类型对象结果 | |
| double applyAsDouble(double left, double right) | 接收两个double值,返回一个double结果 | |
| int applyAsInt(int left, int right) | 接收两个int值,返回一个int结果 | |
| long applyAsLong(long left, long right) | 接收两个long值,返回一个long结果 |
使用案例:
import java.util.function.BinaryOperator;
import java.util.function.DoubleBinaryOperator;
import java.util.function.DoubleUnaryOperator;
import java.util.function.UnaryOperator;
public class FunctionInterfaceFunctionTypeOperator {
public static void main(String[] args) {
// UnaryOperator<T>
UnaryOperator<String> unaryOperator = new UnaryOperator<>() {
@Override
public String apply(String s) {
return s;
}
};
String weew12 = unaryOperator.apply("weew12");
System.out.println(weew12);
// DoubleUnaryOperator
DoubleUnaryOperator doubleUnaryOperator = new DoubleUnaryOperator() {
@Override
public double applyAsDouble(double operand) {
return operand / 2.0;
}
};
double v = doubleUnaryOperator.applyAsDouble(16);
System.out.println(v);
// IntUnaryOperator
// 同上略
// LongUnaryOperator
// 同上略
// BinaryOperator<T>
BinaryOperator<String> binaryOperator = new BinaryOperator<>() {
@Override
public String apply(String s, String s2) {
return s + s2;
}
};
String apply = binaryOperator.apply("weew12", " hello");
System.out.println(apply);
// DoubleBinaryOperator
DoubleBinaryOperator doubleBinaryOperator = new DoubleBinaryOperator() {
@Override
public double applyAsDouble(double left, double right) {
return left + right;
}
};
double v1 = doubleBinaryOperator.applyAsDouble(12.5, 0.5);
System.out.println(v1);
// IntBinaryOperator
// 同上略
// LongBinaryOperator
// 同上略
}
}xxxFunction
| 接口名 | 抽象方法 | 描述 |
|---|---|---|
| R apply(double value) | 接收一个double值,返回一个R类型对象 | |
| R apply(int value) | 接收一个int值,返回一个R类型对象 | |
| R apply(long value) | 接收一个long值,返回一个R类型对象 | |
| double applyAsDouble(T value) | 接收一个T类型对象,返回一个double | |
| int applyAsInt(T value) | 接收一个T类型对象,返回一个int | |
| long applyAsLong(T value) | 接收一个T类型对象,返回一个long | |
| int applyAsInt(double value) | 接收一个double值,返回一个int结果 | |
| long applyAsLong(double value) | 接收一个double值,返回一个long结果 | |
| double applyAsDouble(int value) | 接收一个int值,返回一个double结果 | |
| long applyAsLong(int value) | 接收一个int值,返回一个long结果 | |
| double applyAsDouble(long value) | 接收一个long值,返回一个double结果 | |
| int applyAsInt(long value) | 接收一个long值,返回一个int结果 | |
| R apply(T t, U u) | 接收一个T类型和一个U类型对象,返回一个R类型对象结果 | |
| double applyAsDouble(T t, U u) | 接收一个T类型和一个U类型对象,返回一个double | |
| int applyAsInt(T t, U u) | 接收一个T类型和一个U类型对象,返回一个int | |
| long applyAsLong(T t, U u) | 接收一个T类型和一个U类型对象,返回一个long |
使用案例:
import java.util.function.BiFunction;
import java.util.function.DoubleFunction;
import java.util.function.DoubleToIntFunction;
import java.util.function.ToDoubleFunction;
public class FunctionInterfaceFunctionTypeFunction {
public static void main(String[] args) {
//DoubleFunction<R>
DoubleFunction<String> doubleFunction = new DoubleFunction<>() {
@Override
public String apply(double value) {
return String.valueOf(value);
}
};
String apply = doubleFunction.apply(12.5);
System.out.println(apply);
//IntFunction<R>
// 同上略
//LongFunction<R>
// 同上略
//ToDoubleFunction<T>
ToDoubleFunction<String> toDoubleFunction = new ToDoubleFunction<>() {
@Override
public double applyAsDouble(String value) {
return Double.parseDouble(value);
}
};
double v = toDoubleFunction.applyAsDouble("12.5");
System.out.println(v);
//ToIntFunction<T>
// 同上略
//ToLongFunction<T>
// 同上略
//DoubleToIntFunction
DoubleToIntFunction doubleToIntFunction = new DoubleToIntFunction() {
@Override
public int applyAsInt(double value) {
return (int) (value / 2);
}
};
int i = doubleToIntFunction.applyAsInt(12.0);
System.out.println(i);
//DoubleToLongFunction
// 同上略
//IntToDoubleFunction
// 同上略
//IntToLongFunction
// 同上略
//LongToDoubleFunction
// 同上略
//LongToIntFunction
// 同上略
//BiFunction<T,U,R>
BiFunction<String, Integer, Double> biFunction = new BiFunction<>() {
@Override
public Double apply(String s, Integer integer) {
return Double.parseDouble(s) + integer;
}
};
Double apply1 = biFunction.apply("12.50", 12);
System.out.println(apply1);
//ToDoubleBiFunction<T,U>
// 同上略
//ToIntBiFunction<T,U>
// 同上略
//ToLongBiFunction<T,U>
// 同上略
}
}类型4:判断型接口
boolean
| 接口名 | 抽象方法 | 描述 |
|---|---|---|
| boolean test(T t, U u) | 接收两个对象 | |
| boolean test(double value) | 接收一个double值 | |
| boolean test(int value) | 接收一个int值 | |
| boolean test(long value) | 接收一个long值 |
使用案例:
import java.util.function.BiPredicate;
import java.util.function.DoublePredicate;
public class FunctionInterfacePredicateType {
public static void main(String[] args) {
// BiPredicate<T,U>
BiPredicate<String, String> biPredicate = new BiPredicate<>() {
@Override
public boolean test(String s, String s2) {
return s.endsWith(s2);
}
};
boolean test = biPredicate.test("weew12.png", ".png");
System.out.println(test);
// DoublePredicate
DoublePredicate doublePredicate = new DoublePredicate() {
@Override
public boolean test(double value) {
return value > 12.0;
}
};
boolean test1 = doublePredicate.test(15.0);
System.out.println(test1);
// IntPredicate
// 同上略
// LongPredicate
// 同上略
}
}补充
1.消费型接口- 在
JDK1.8中Collection集合接口的父接口Iterable接口中增加了一个默认方法:public default void forEach(Consumer<? super T> action)遍历Collection集合的每个元素,执行xxx消费操作 - 在
JDK1.8中Map集合接口中增加了一个默认方法:public default void forEach(BiConsumer<? super K,? super V> action)遍历Map集合的每对映射关系,执行xxx消费操作
- 在
2.供给型接口- 在
JDK1.8中增加了StreamAPI,java.util.stream.Stream是一个数据流,这个类型有一个静态方法:public static <T> Stream<T> generate(Supplier<T> s)可以创建Stream的对象;又包含一个forEach方法可以遍历流中的元素:public void forEach(Consumer<? super T> action)- :调用
Stream的generate方法,来产生一个流对象,调用Math.random()方法来产生数据,为Supplier函数式接口的形参赋值,最后调用forEach方法遍历流中的数据查看结果
- :调用
- 在
import java.util.stream.Stream;
public class StreamGenerateSupplierInterfaceTest {
public static void main(String[] args) {
Stream<Integer> generate = Stream.generate(() -> ((Integer) (int) (Math.random() * 100)));
generate.forEach(integer -> System.out.println(integer));
}
}3.函数型接口- 在
JDK1.8时Map接口增加了很多方法,例如:public default void replaceAll(BiFunction<? super K,? super V,? extends V> function)按照function指定的操作替换map中的value;public default void forEach(BiConsumer<? super K,? super V> action)遍历Map集合的每对映射关系,执行xxx消费操作
- 在
import java.util.HashMap;
/**
* Description:
* Collection 判断型接口测试
* 需求:
* 1. 添加一些字符串到一个Collection集合中
* 2. 调用forEach遍历集合
* 3. 调用removeIf方法,删除其中字符串的长度<5的
* 4. 再次调用forEach遍历集合
*/
public class CollectionFunctionInterfaceTest1 {
public static void main(String[] args) {
HashMap<Integer, MfEmployee> employees = new HashMap<>();
MfEmployee e1 = new MfEmployee(1, "张三", 8000);
MfEmployee e2 = new MfEmployee(2, "李四", 9000);
MfEmployee e3 = new MfEmployee(3, "王五", 10000);
MfEmployee e4 = new MfEmployee(4, "赵六", 11000);
MfEmployee e5 = new MfEmployee(5, "钱七", 12000);
employees.put(e1.getId(), e1);
employees.put(e2.getId(), e2);
employees.put(e3.getId(), e3);
employees.put(e4.getId(), e4);
employees.put(e5.getId(), e5);
// 遍历forEach
employees.forEach((k, v) -> System.out.println(k + " " + v));
// 将其中薪资低于10000元的 薪资设置为10000 replaceAll
employees.replaceAll((k, v) -> {
if (v.getSalary() < 10000) {
v.setSalary(10000);
}
return v;
});
// 遍历forEach
employees.forEach((k, v) -> System.out.println(k + " " + v));
}
}
class MfEmployee {
private int id;
private String name;
private double salary;
public MfEmployee(int id, String name, double salary) {
this.id = id;
this.name = name;
this.salary = salary;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getSalary() {
return salary;
}
public void setSalary(double salary) {
this.salary = salary;
}
@Override
public String toString() {
return "MfEmployee{" +
"id=" + id +
", name='" + name + '\'' +
", salary=" + salary +
'}';
}
}4.判断型接口JDK1.8时,Collecton接口增加了以下方法:public default boolean removeIf(Predicate<? super E> filter)用于删除集合中满足filter指定的条件判断的元素,public default void forEach(Consumer<? super T> action)遍历Collection集合的每个元素,执行xxx消费型操作1
import java.util.ArrayList;
/**
* Description:
* Collection 判断型接口测试
* 需求:
* 1. 添加一些字符串到一个Collection集合中
* 2. 调用forEach遍历集合
* 3. 调用removeIf方法,删除其中字符串的长度<5的
* 4. 再次调用forEach遍历集合
*/
public class CollectionFunctionInterfaceTest {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("hello");
list.add("java");
list.add("atguigu");
list.add("ok");
list.add("yes");
// 遍历
list.forEach((s -> System.out.println(s)));
System.out.println();
// 删除
list.removeIf((s -> s.length() < 5));
// 遍历
list.forEach((s -> System.out.println(s)));
}
}案例2:
import java.util.ArrayList;
import java.util.Arrays;
import java.util.function.Predicate;
/**
* Description:
* Collection 判断型接口测试
* 需求:
* 1. 声明一个Employee员工类型,包含编号、姓名、性别,年龄,薪资。
* 2. 声明一个EmployeeSerice员工管理类,包含一个ArrayList集合的属性all,在EmployeeSerice的构造器中,创建一些员工对象,为all集合初始化。
* 3. 在EmployeeSerice员工管理类中,声明一个方法:ArrayList get(Predicate p),即将满足p指定的条件的员工,添加到一个新的ArrayList 集合中返回。
* 4. 在测试类中创建EmployeeSerice员工管理类的对象,并调用get方法,分别获取:
* a. 所有员工对象
* b. 所有年龄超过35的员工
* c. 所有薪资高于15000的女员工
* d. 所有编号是偶数的员工
* e. 名字是“张三”的员工
* f. 年龄超过25,薪资低于10000的男员工
*/
public class CollectionFunctionInterfaceTest2 {
public static void main(String[] args) {
CfEmployeeService cfEmployeeService = new CfEmployeeService();
//所有员工对象
cfEmployeeService.get(e -> true).forEach(e -> System.out.println(e));
System.out.println();
//所有年龄超过35的员工
cfEmployeeService.get(e -> e.getAge() > 35).forEach(e -> System.out.println(e));
System.out.println();
//所有薪资高于15000的女员工
cfEmployeeService.get(e -> e.getSalary() > 15000 && e.getGender() == '女').forEach(e -> System.out.println(e));
System.out.println();
//所有编号是偶数的员工
cfEmployeeService.get(e -> e.getId() % 2 == 0).forEach(e -> System.out.println(e));
System.out.println();
//名字是“张三”的员工
cfEmployeeService.get(e -> e.getName() == "张三").forEach(e -> System.out.println(e));
System.out.println();
//年龄超过25,薪资低于10000的男员工
cfEmployeeService.get(e -> e.getAge() > 25 && e.getSalary() < 10000).forEach(e -> System.out.println(e));
System.out.println();
}
}
/**
* 员工类
*/
class CfEmployee {
private int id;
private String name;
private char gender;
private int age;
private double salary;
public CfEmployee() {
}
public CfEmployee(int id, String name, char gender, int age, double salary) {
this.id = id;
this.name = name;
this.gender = gender;
this.age = age;
this.salary = salary;
}
public int getId() {
return id;
}
public String getName() {
return name;
}
public char getGender() {
return gender;
}
public int getAge() {
return age;
}
public double getSalary() {
return salary;
}
@Override
public String toString() {
return "CfEmployee{" +
"id=" + id +
", name='" + name + '\'' +
", gender=" + gender +
", age=" + age +
", salary=" + salary +
'}';
}
}
/**
* 员工管理类
*/
class CfEmployeeService {
private ArrayList<CfEmployee> all;
public CfEmployeeService() {
all = new ArrayList<CfEmployee>();
all.add(new CfEmployee(1, "张三", '男', 33, 8000));
all.add(new CfEmployee(2, "翠花", '女', 23, 18000));
all.add(new CfEmployee(3, "无能", '男', 46, 8000));
all.add(new CfEmployee(4, "李四", '女', 23, 9000));
all.add(new CfEmployee(5, "老王", '男', 23, 15000));
all.add(new CfEmployee(6, "大嘴", '男', 23, 11000));
}
public ArrayList<CfEmployee> get(Predicate<CfEmployee> p) {
ArrayList<CfEmployee> cfEmployees = new ArrayList<>();
for (CfEmployee cfEmployee : all) {
if (p.test(cfEmployee)) {
cfEmployees.add(cfEmployee);
}
}
return cfEmployees;
}
}Java8新特性:方法引用与构造器引用
Lambda表达式是可以简化函数式接口的变量或形参赋值的语法,而 Lambda
方法引用
当要传递给Lambda体的操作,已经有实现的方法了,可以使用方法引用!
方法引用可以看做是Lambda表达式深层次的表达。换句话说,方法引用就是Lambda表达式,也就是函数式接口的一个实例,通过方法的名字来指向一个方法,Lambda。
语法糖(Syntactic sugar),也译为糖衣语法,是由英国计算机科学家彼得·约翰·兰达(Peter J. Landin)发明的一个术语,,通常来说使用语法糖能够增加程序的可读性,从而减少程序代码出错的机会。
格式
- 格式:使用方法引用操作符
::将类(或对象) 与方法名分隔开- 两个中间不能有空格,而且必须英文状态下半角输入
- 如下三种主要使用情况:
- 情况
1:对象::实例方法名 - 情况
2:类::静态方法名 - 情况
3:类::实例方法名
- 情况
使用前提
1:Lambda体只有一个语句,并且是通过调用一个对象的/类现有的方法来完成的- 例如:
System.out对象,调用println()方法来完成Lambda体Math类,调用random()静态方法来完成Lambda体
- 例如:
2:- 针对情况
1(对象::实例方法名):函数式接口中的抽象方法a在被重写时使用了b。ab,则可以使用方法b实现对方法a的重写、替换 - 针对情况
2(类::静态方法名):函数式接口中的抽象方法a在被重写时使用了b。ab,则可以使用方法b实现对方法a的重写、替换 - 针对情况
3(类::实例方法名):函数式接口中的抽象方法a在被重写时使用了b。abanbn-1a1ban-1n-1 - 例如:
t->System.out.println(t)() -> Math.random()
- 针对情况
举例
import java.io.PrintStream;
import java.util.Comparator;
import java.util.function.BiPredicate;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.function.Supplier;
public class MethodReferenceTest {
public static void main(String[] args) {
// ================ 情况1 对象::实例方法 ================
// Consumer accept()方法
// PrintStream println()方法
Consumer<String> consumer = s -> System.out.println(s);
consumer.accept("weew12");
PrintStream out = System.out;
Consumer<String> consumer2 = out::println;
consumer2.accept("weew12");
// Supplier get()方法
// CfEmployee getName()方法
CfEmployee cfEmployee = new CfEmployee(1001, "weew12", '男', 25, 15000);
Supplier<String> supplier = () -> cfEmployee.getName();
System.out.println(supplier.get());
Supplier<String> supplier2 = cfEmployee::getName;
System.out.println(supplier2.get());
// ================ 情况2 类::静态方法 ================
// Comparator compare()方法
// Integer compare()方法
Comparator<Integer> comparator = (t1, t2) -> Integer.compare(t1, t2);
System.out.println(comparator.compare(12, 21));
Comparator<Integer> comparator2 = Integer::compare;
System.out.println(comparator2.compare(12, 21));
// Function apply()方法
// Math round()方法
Function<Double, Long> function = (aDouble -> Math.round(aDouble));
System.out.println(function.apply(12.3));
Function<Double, Long> function2 = Math::round;
System.out.println(function2.apply(12.3));
// ================ 情况3 类::实例方法 ================
// Comparator compare()方法
// String t1.compare(t2)方法
Comparator<String> comparator3 = (s1, s2) -> s1.compareTo(s2);
System.out.println(comparator3.compare("abc", "abd"));
Comparator<String> comparator4 = String::compareTo;
System.out.println(comparator4.compare("abc", "abd"));
// BiPredicate test()方法
// String t1.equals(t2)方法
BiPredicate<String, String> biPredicate = (s1, s2) -> s1.equals(s2);
System.out.println(biPredicate.test("abc", "abc"));
BiPredicate<String, String> biPredicate2 = String::equals;
System.out.println(biPredicate2.test("abc", "abc"));
// Function apply()方法
// CfEmployee getName()方法
CfEmployee cfEmployee2 = new CfEmployee(1001, "weew13", '男', 25, 25000);
Function<CfEmployee, String> function3 = e -> e.getName();
System.out.println(function3.apply(cfEmployee2));
Function<CfEmployee, String> function4 = CfEmployee::getName;
System.out.println(function4.apply(cfEmployee2));
}
}构造器引用
LambdaLambda
格式
类名::new
举例
import java.util.function.BiFunction;
import java.util.function.Function;
import java.util.function.Supplier;
public class ConstructorReferenceTest {
public static void main(String[] args) {
// Supplier get()方法
// CrEmployee 构造器:CrEmployee()
Supplier<CrEmployee> supplier = () -> new CrEmployee();
CrEmployee crEmployee = supplier.get();
System.out.println(crEmployee);
Supplier<CrEmployee> supplier2 = CrEmployee::new;
CrEmployee crEmployee1 = supplier2.get();
System.out.println(crEmployee1);
// Function apply()方法
// CrEmployee 构造器:CrEmployee(int id)
Function<Integer, CrEmployee> function = id -> new CrEmployee(id);
CrEmployee apply = function.apply(2001);
System.out.println(apply);
Function<Integer, CrEmployee> function2 = CrEmployee::new;
CrEmployee apply1 = function2.apply(2001);
System.out.println(apply1);
// BiFunction apply
// CrEmployee 构造器:CrEmployee(int id, String name)
BiFunction<Integer, String, CrEmployee> biFunction = (id, name) -> new CrEmployee(id, name);
CrEmployee weew12 = biFunction.apply(2001, "weew12");
System.out.println(weew12);
BiFunction<Integer, String, CrEmployee> biFunction2 = CrEmployee::new;
CrEmployee weew121 = biFunction2.apply(2001, "weew12");
System.out.println(weew121);
}
}
/**
* 员工类
*/
class CrEmployee {
private int id;
private String name;
public CrEmployee() {
}
public CrEmployee(int id) {
this.id = id;
}
public CrEmployee(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "CrEmployee{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}数组构造引用
LambdaLambda
格式
数组类型名::new
举例
import java.util.Arrays;
import java.util.function.Function;
public class ArrayReferenceTest {
public static void main(String[] args) {
// Function apply()
Function<Integer, String[]> function = len -> new String[len];
String[] apply = function.apply(5);
System.out.println(Arrays.toString(apply));
Function<Integer, String[]> function2 = String[]::new;
String[] apply1 = function2.apply(5);
System.out.println(Arrays.toString(apply1));
}
}Java8新特性:强大的Stream API
说明
Java8中有两大最为重要的改变,第一个是Lambda表达式;另外一个则是Stream APIStream APIjava.util.stream) 把真正的函数式编程风格引入到Java,这是目前为止对Java类库最好的补充,因为Stream API可以极大提供Java程序员的生产力,让程序员写出高效率、干净、简洁的代码Stream是Java8中处理集合的关键抽象概念,它可以指定希望对集合进行的操作,可以执行非常复杂的查找、过滤、映射数据等操作。使用Stream API对集合数据进行操作,就类似使用SQL执行的数据库查询,也可以使用Stream API来并行执行操作。简言之,Stream API
为什么要使用Stream API
实际开发中,项目中多数数据源都来自于MySQL、Oracle等,但现在数据源可以更多了,有MongDB,Redis等,而这些NoSQL的数据就需要Java层面去处理。
什么是Stream
Stream。
Stream和Collection集合的区别:
Collection是一种静态的内存数据结构,重点是数据;Stream是有关计算的重点是计算Collection是主要面向内存,存储在内存中;Stream主要是面向CPU,通过CPU实现计算
StreamStreamStreamStreamStream
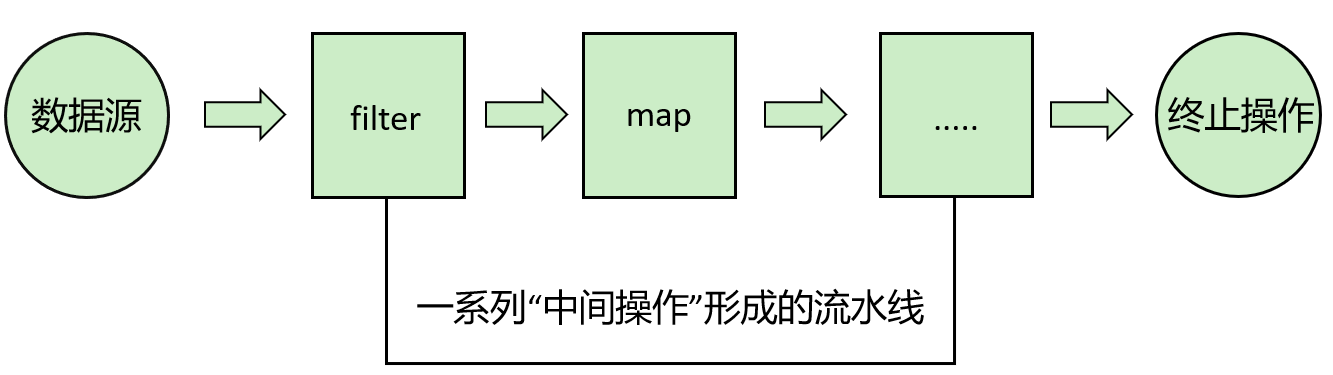
Stream的操作三个步骤
1.创建Stream- 一个数据源,如:集合、数组,获取一个流
2.中间操作- 每次处理都会返回一个持有结果的新
Stream,即:中间操作的方法返回值仍然是Stream类型的对象。中间操作可以是个操作链,可对数据源的数据进行n次处理,
- 每次处理都会返回一个持有结果的新
3.终止操作/终端操作StreamStreamStream
创建Stream实例
方式1:通过集合
Java8中的Collection接口被扩展,提供了两个获取流的方法:
default Stream stream(): 返回一个default Stream parallelStream(): 返回一个
list = Arrays.asList(1,2,3,4,5);
// JDK1.8中,Collection系列集合增加了方法
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> stream = integers.stream();
Stream<Integer> integerStream = integers.parallelStream();方式2:通过数组
Java8中的Arrays的静态方法stream()可以获取数组流:
static Stream stream(T[] array)public static IntStream stream(int[] array)public static LongStream stream(long[] array)public static DoubleStream stream(double[] array)
String[] arr = {"weew12", "hello"};
Stream<String> stream1 = Arrays.stream(arr);
int[] arr2 = {1, 2, 3, 4, 5};
IntStream stream2 = Arrays.stream(arr2);方式3:通过Stream的of()
可以调用Stream类静态方法of(), 通过显示值创建一个流,它可以接收任意数量的参数。
public static Stream of(T... values):返回一个流
Stream<Integer> integerStream1 = Stream.of(1, 2, 3, 4, 5);
integerStream1.forEach(System.out::println);方式4:创建无限流
可以使用静态方法 Stream.iterate() 和 Stream.generate(),创建无限流。
- 迭代:
public static Stream iterate(final T seed, final UnaryOperator f) - 生成:
public static Stream generate(Supplier s)
// 迭代 public static Stream iterate(final T seed, final UnaryOperator f)
UnaryOperator<Integer> unaryOperator = integer -> integer + 2;
// 简写:Stream<Integer> iterate = Stream.iterate(0, x -> x + 2);
Stream<Integer> iterate = Stream.iterate(0, unaryOperator);
iterate.limit(10).forEach(System.out::println);
// 生成 public static Stream generate(Supplier s)
Supplier<Double> supplier = () -> Math.random();
// 简写:Stream<Double> generate = Stream.generate(Math::random);
Stream<Double> generate = Stream.generate(supplier);
generate.limit(10).forEach(System.out::println);中间操作
1 筛选与切片
filter(Predicate p):接收Lambda,从流中排除某些元素distinct():筛选,通过流所生成元素的hashCode()和equals()去除重复元素limit(long maxSize):截断流,使其元素不超过给定数量skip(long n):返回扔掉前n个元素的流,若元素不足n个,则返回空流,与limit(n)互补
import java.util.stream.Stream;
public class StreamMiddleOperate1 {
public static void main(String[] args) {
// filter 过滤操作
Stream<Integer> integerStream = Stream.of(1, 2, 3, 4, 5, 6);
Stream<Integer> integerStream1 = integerStream.filter(integer -> integer % 2 == 0);
integerStream1.forEach(System.out::println);
System.out.println();
// distinct 去重操作
Stream<Integer> integerStream2 = Stream.of(1, 2, 3, 4, 5, 6, 2, 2, 3, 3, 4, 4, 5);
Stream<Integer> distinct = integerStream2.distinct();
distinct.forEach(System.out::println);
System.out.println();
// limit 截断
Stream<Integer> integerStream3 = Stream.of(1, 2, 3, 4, 5, 6, 2, 2, 3, 3, 4, 4, 5);
Stream<Integer> limit = integerStream3.limit(5);
limit.forEach(System.out::println);
System.out.println();
// skip 跳过
Stream<Integer> integerStream4 = Stream.of(1, 2, 3, 4, 5, 6);
Stream<Integer> skip = integerStream4.skip(3);
skip.forEach(System.out::println);
System.out.println();
}
}2 映 射
map(Function f):接收一个函数,该函数会被应用到每个元素上,并将其映射成一个新的元素mapToDouble(ToDoubleFunction f):函数被应用到每个元素上,产生一个新的DoubleStreammapToInt(ToIntFunction f):函数会被应用到每个元素上,产生一个新的IntStreammapToLong(ToLongFunction f):函数会被应用到每个元素上,产生一个新的LongStreamflatMap(Function f):函数将流中的每个值都换成另一个流,然后把所有流连接成一个流
import java.util.Arrays;
import java.util.function.Function;
import java.util.stream.DoubleStream;
import java.util.stream.Stream;
public class StreamMiddleOperate2 {
public static void main(String[] args) {
// map
Stream<Integer> integerStream = Stream.of(1, 2, 3, 4, 5, 6);
Stream<Integer> integerStream1 = integerStream.map(integer -> integer + 1);
integerStream1.forEach(System.out::println);
// mapToDouble
Stream<Integer> integerStream2 = Stream.of(1, 2, 3, 4, 5, 6);
DoubleStream doubleStream = integerStream2.mapToDouble(Double::valueOf);
doubleStream.forEach(System.out::println);
// mapToInt
// 略
// mapToLong
// 略
// flatMap
Stream<String> stringStream = Stream.of("item 1", "item 2", "item 3", "item 4", "item 5");
Stream<String> stringStream1 = stringStream.flatMap((Function<String, Stream<String>>) s -> Arrays.stream(s.split(" ")));
stringStream1.forEach(System.out::println);
}
}3 排序
sorted():sorted(Comparator com):
import java.util.Comparator;
import java.util.stream.Stream;
public class StreamMiddleOperate3 {
public static void main(String[] args) {
// sorted()
Stream<Integer> integerStream = Stream.of(9, 6, 3, 7, 1, 2, 15, 99, 22, 789);
Stream<Integer> sorted = integerStream.sorted();
sorted.forEach(System.out::println);
// sorted(Comparator)
Comparator<Integer> comparator = (o1, o2) -> -Integer.compare(o1, o2);
Stream<Integer> integerStream2 = Stream.of(9, 6, 3, 7, 1, 2, 15, 99, 22, 789);
Stream<Integer> sorted1 = integerStream2.sorted(comparator);
sorted1.forEach(System.out::println);
}
}终止操作
- 终端操作会从流的流水线生成结果,其结果可以是任何不是流的值,例如:
List、Integer、甚至是void
1 匹配与查找
allMatch(Predicate p):检查是否anyMatch(Predicate p):检查是否noneMatch(Predicate p):检查是否findFirst():返回findAny():返回count():返回流中max(Comparator c):返回min(Comparator c):返回forEach(Consumer c):。使用Collection接口需要用户去做迭代,称为外部迭代。相反,Stream API使用内部迭代——它帮忙把迭代做了
import java.util.Optional;
import java.util.stream.Stream;
public class StreamEndOperate1 {
public static void main(String[] args) {
// allMatch(Predicate p):检查是否匹配所有元素
boolean b = Stream.of(1, 3, 5, 7, 9).allMatch(integer -> integer % 2 == 0);
System.out.println(b);
System.out.println();
// anyMatch(Predicate p):检查是否至少匹配一个元素
boolean b1 = Stream.of(1, 3, 5, 7, 9).anyMatch(integer -> integer % 2 == 0);
System.out.println(b1);
System.out.println();
// noneMatch(Predicate p):检查是否没有匹配所有元素
boolean b2 = Stream.of(1, 3, 5, 7, 9).noneMatch(integer -> integer % 2 == 0);
System.out.println(b2);
System.out.println();
// findFirst():返回第一个元素
Optional<Integer> first = Stream.of(1, 2, 3, 4, 5).findFirst();
System.out.println(first.get());
System.out.println();
// findAny():返回当前流中的任意元素 [顺序流的话通常是返回流中的第一个元素]
Optional<Integer> any = Stream.of(1, 2, 3, 4, 5).findAny();
System.out.println(any.get());
System.out.println();
// count():返回流中元素总数
long count = Stream.of(1, 2, 3, 4, 5).count();
System.out.println(count);
System.out.println();
// max(Comparator c):返回流中最大值
Optional<Integer> max = Stream.of(1, 2, 3, 4, 5).max(Integer::compare);
System.out.println(max.get());
System.out.println();
// min(Comparator c):返回流中最小值
Optional<Integer> min = Stream.of(1, 2, 3, 4, 5).min(Integer::compare);
System.out.println(min.get());
System.out.println();
// forEach(Consumer c):内部迭代。使用Collection接口需要用户去做迭代,称为外部迭代。相反,Stream API使用内部迭代——它帮忙把迭代做了
Stream.of(1, 2, 3, 4, 5).forEach(System.out::println);
System.out.println();
}
}2 归约
reduce(T identity, BinaryOperator b):可以将流中元素反复结合,得到一个值,返回T,reducereduce(BinaryOperator b):可以将流中元素反复结合起来,得到一个值,返回Optional
备注:map和reduce的连接通常称为map-reduce模式,因Google用它来进行网络搜索而出名
import java.util.Optional;
import java.util.stream.Stream;
public class StreamEndOperate2 {
public static void main(String[] args) {
// reduce(T identity, BinaryOperator b):可以将流中元素反复结合,得到一个值,返回T
// 这里实际上就是找最大值并返回
Integer reduce = Stream.of(1, 2, 4, 5, 7, 8).reduce(0, (t1, t2) -> t1 > t2 ? t1 : t2);
System.out.println(reduce);
System.out.println();
// reduce(BinaryOperator b):可以将流中元素反复结合起来,得到一个值,返回Optional
Optional<Integer> reduce1 = Stream.of(1, 2, 4, 5, 7, 8).reduce((t1, t2) -> t1 > t2 ? t1 : t2);
System.out.println(reduce1.get());
System.out.println();
}
}3 收集
collect(Collector c):将流转换为其他形式,接收一个Collector接口的实现,用于给Stream中元素做汇总的方法Collector:CollectorCollectorListMap
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class StreamEndOperate3 {
public static void main(String[] args) {
List<Integer> collect = Stream.of(1, 2, 4, 5, 7, 8)
.filter(integer -> integer % 2 == 0)
.collect(Collectors.toList());
System.out.println(collect);
}
}另外:Collectors
| 方法 | 返回类型 | 作用 |
|---|---|---|
| Collector<T, ?, List> | 把流中元素收集到List | |
| Collector<T, ?, Set> | 把流中元素收集到Set | |
| Collector<T, ?, C> | 把流中元素收集到创建的集合 | |
| Collector<T, ?, Long> | 计算流中元素的个数 | |
| Collector<T, ?, Integer> | 对流中元素的整数属性求和 | |
| Collector<T, ?, Double> | 计算流中元素Integer属性的平均值 | |
| Collector<T, ?, IntSummaryStatistics> | 收集流中Integer属性的统计值。 | |
| Collector<CharSequence, ?, String> | 连接流中每个字符串 | |
| Collector<T, ?, Optional> | 从一个作为累加器的初始值开始,利用BinaryOperator与流中元素逐个结合,从而归约成单个值 | |
| Collector<T,A,RR> | 包裹另一个收集器, | |
| Collector<T, ?, Optional> | 根据比较器选择最大值 | |
| Collector<T, ?, Optional> | 根据比较器选择最小值 | |
| Collector<T, ?, Map<K, List>> | Map<K, List<T>> | |
| Collector<T, ?, Map<Boolean, List>> | truefalse |
案例代码:
import java.util.*;
import java.util.stream.Collector;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class StreamEndOperate4 {
public static void main(String[] args) {
// toList
Integer[] arr = {1, 2, 3, 4, 5};
List<Integer> collect = Stream.of(arr).collect(Collectors.toList());
// 输出:[1, 2, 3, 4, 5]
System.out.println(collect);
// toSet
Integer[] arr2 = {1, 1, 2, 2, 3, 3, 4, 4, 5, 5};
Set<Integer> collect1 = Stream.of(arr2).collect(Collectors.toSet());
// 输出:[1, 2, 3, 4, 5]
System.out.println(collect1);
// toCollection
Integer[] arr3 = {1, 2, 3, 4, 5};
ArrayList<Integer> collect2 = Arrays.stream(arr3).collect(Collectors.toCollection(ArrayList::new));
// 输出:[1, 2, 3, 4, 5]
System.out.println(collect2);
// counting
Long collect3 = Stream.of(1, 2, 3, 4).collect(Collectors.counting());
// 输出:4
System.out.println(collect3);
// summingInt
String[] arr4 = {"1", "2", "3", "4", "5"};
Integer collect4 = Arrays.stream(arr4).collect(Collectors.summingInt(Integer::parseInt));
// 输出:15
System.out.println(collect4);
// averagingInt
Double collect5 = Arrays.stream(arr4).collect(Collectors.averagingInt(Integer::parseInt));
// 输出:3.0
System.out.println(collect5);
// summarizingInt
IntSummaryStatistics collect6 = Stream.of(1, 2, 3, 4, 5).collect(Collectors.summarizingInt(Integer::intValue));
// 输出:
// sum = 15
// Average = 3.0
// Max = 5
// Min = 1
// Count = 5
System.out.println("sum = " + collect6.getSum());
System.out.println("Average = " + collect6.getAverage());
System.out.println("Max = " + collect6.getMax());
System.out.println("Min = " + collect6.getMin());
System.out.println("Count = " + collect6.getCount());
// joining
String[] arr5 = {"1", "2", "3", "4", "5"};
String collect7 = Arrays.stream(arr5).collect(Collectors.joining());
// 输出:12345
System.out.println(collect7);
// reducing --> Collector<T, ?, Optional> 三个参数的版本
String[] arr6 = {"1", "2", "3", "4", "5"};
Integer collect8 = Arrays.stream(arr6).collect(Collectors.reducing(0, str -> Integer.parseInt(str), Integer::sum));
// 输出:15
System.out.println(collect8);
// collectingAndThen
// 解释:Collectors.collectingAndThen(Collectors.toList(), List::size)
// 分别指定搜集方式 和 收集后的计算方法
ArrayList<Integer> integers = new ArrayList<>();
for (int i = 0; i < 5; i++) {
integers.add(i);
integers.add(i);
}
Integer collect9 = integers.stream().collect(Collectors.collectingAndThen(Collectors.toSet(), Set::size));
// 输出:5
System.out.println(collect9);
// maxBy
List<Integer> list = Arrays.asList(10, 20, 30, 40, 50);
Optional<Integer> collect10 = list.stream().collect(Collectors.maxBy(Comparator.comparingInt(Integer::intValue)));
// 输出:50
System.out.println(collect10.get());
// minBy
Optional<Integer> collect11 = list.stream().collect(Collectors.minBy(Comparator.comparingInt(Integer::intValue)));
// 输出:10
System.out.println(collect11.get());
// groupingBy
class InnerItem {
private Integer value;
private String group;
public InnerItem(Integer value, String group) {
this.value = value;
this.group = group;
}
public Integer getValue() {
return value;
}
public String getGroup() {
return group;
}
@Override
public String toString() {
return "InnerItem{" +
"value=" + value +
", group='" + group + '\'' +
'}';
}
}
ArrayList<InnerItem> innerItems = new ArrayList<>();
innerItems.add(new InnerItem(1, "group1"));
innerItems.add(new InnerItem(2, "group2"));
innerItems.add(new InnerItem(3, "group2"));
innerItems.add(new InnerItem(4, "group2"));
// 输出:[InnerItem{value=1, group='group1'}, InnerItem{value=2, group='group2'}, InnerItem{value=3, group='group2'}, InnerItem{value=4, group='group2'}]
System.out.println(innerItems);
Map<String, List<InnerItem>> collect12 = innerItems.stream().collect(Collectors.groupingBy(InnerItem::getGroup));
// 输出:{group2=[InnerItem{value=2, group='group2'}, InnerItem{value=3, group='group2'}, InnerItem{value=4, group='group2'}], group1=[InnerItem{value=1, group='group1'}]}
System.out.println(collect12);
// partitioningBy
Map<Boolean, List<InnerItem>> collect13 = innerItems.stream().collect(Collectors.partitioningBy(innerItem -> innerItem.getValue() >= 4));
// 输出:{false=[InnerItem{value=1, group='group1'}, InnerItem{value=2, group='group2'}, InnerItem{value=3, group='group2'}], true=[InnerItem{value=4, group='group2'}]}
System.out.println(collect13);
}
}Java9新增API
Stream实例化方法
ofNullable()的使用:Java8中Stream不能完全为null,否则会报空指针异常;而Java9中的ofNullable方法允许我们创建一个单元素Stream,可以包含一个非空元素,也可以创建一个空Stream
- 案例代码:
import java.util.ArrayList;
import java.util.stream.Stream;
public class Java9StreamOfNullable {
public static void main(String[] args) {
// 报 NullPointerException
// Stream<Object> objectStream = Stream.of(null);
// System.out.println(objectStream.count());
// 不报异常,允许通过
Stream<String> stringStream = Stream.of("AA", "BB", null);
// 输出:3
System.out.println(stringStream.count());
// 不报异常,允许通过
ArrayList<String> strings = new ArrayList<>();
strings.add("AA");
strings.add(null);
// 输出:2
System.out.println(strings.stream().count());
// ofNullable() 允许值为null
Stream<Object> objectStream = Stream.ofNullable(null);
// 输出:0
System.out.println(objectStream.count());
Stream<String> stringStream1 = Stream.ofNullable("hello weew12");
// 输出:1
System.out.println(stringStream1.count());
// iterator()重载的使用
// 原有的终止方式
/*
public static <T> Stream<T> iterate(T seed, UnaryOperator<T> f)
*/
Stream.iterate(1, integer -> integer + 1).limit(10).forEach(System.out::println);
System.out.println();
// 现在的终止方式
/*
public static <T> Stream<T> iterate(T seed, Predicate<? super T> hasNext, UnaryOperator<T> next)
*/
Stream.iterate(1, integer -> integer < 10, integer -> integer + 1).forEach(System.out::println);
}
}练习
现在有两个ArrayList集合存储队伍当中的多个成员姓名,要求使用传统的for循环或增强for循环依次进行以下操作步骤:
1.第一个队伍只要名字为3个字的成员姓名,存储到一个新集合中2.第一个队伍筛选之后只要前3个人,存储到一个新集合中3.第二个队伍只要姓张的成员姓名,存储到一个新集合中4.第二个队伍筛选之后不要前2个人,存储到一个新集合中5.将两个队伍合并为一个队伍,存储到一个新集合中6.根据姓名创建Person对象,存储到一个新集合中7.打印整个队伍的Person对象信息
Person类:
public class Person {
private String name;
public Person() {
}
public Person(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Person{name='" + name + "'}";
}
}操作代码:
public static void main(String[] args) {
//第一支队伍
ArrayList<String> one = new ArrayList<>();
one.add("迪丽热巴");
one.add("宋远桥");
one.add("苏星河");
one.add("石破天");
one.add("石中玉");
one.add("老子");
one.add("庄子");
one.add("洪七公");
//第二支队伍
ArrayList<String> two = new ArrayList<>();
two.add("古力娜扎");
two.add("张无忌");
two.add("赵丽颖");
two.add("张三丰");
two.add("尼古拉斯赵四");
two.add("张天爱");
two.add("张二狗");
// 第一个队伍只要名字为3个字的成员姓名;
// 第一个队伍筛选之后只要前3个人;
Stream<String> streamOne = one.stream().filter(s ‐> s.length() == 3).limit(3);
// 第二个队伍只要姓张的成员姓名;
// 第二个队伍筛选之后不要前2个人;
Stream<String> streamTwo = two.stream().filter(s ‐> s.startsWith("张")).skip(2);
// 将两个队伍合并为一个队伍;
// 根据姓名创建Person对象;
// 打印整个队伍的Person对象信息。
Stream.concat(streamOne, streamTwo).map(Person::new).forEach(System.out::println);
}新语法结构
新的语法结构,将开发者从复杂、繁琐的低层次抽象中逐渐解放出来,以更高层次、更优雅的抽象,既降低代码量,又避免意外编程错误的出现,进而提高代码质量和开发效率。
Java的REPL工具: jShell命令(JDK9)
Java拥有了像Python和Scala之类语言的REPL工具jShell(交互式编程环境:read-evaluate-print-loop),以交互式的方式对语句和表达式进行求值,即写即得、快速运行- 利用
jShell可以在没有创建类的情况下,在命令行里直接声明变量、计算表达式、执行语句 - 使用举例:
调出
jShell
- 获取帮助

- 基本使用
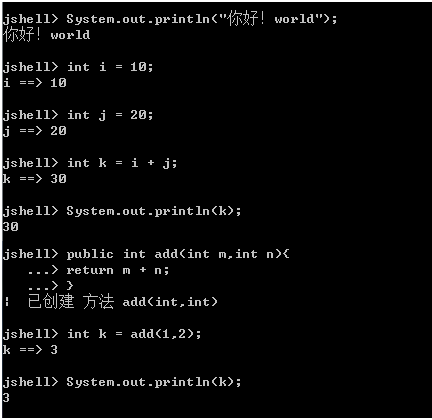
- 导入指定的包

- 默认已经导入如下的所有包:(包含
java.lang包)
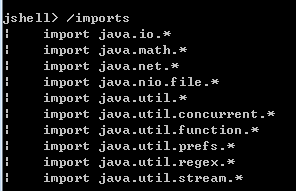
- 只需按下
Tab键,就能自动补全代码

- 列出当前
session里所有有效的代码片段
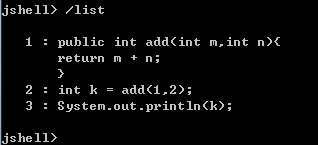
- 查看当前
session下所有创建过的变量
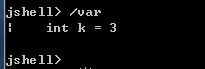
- 查看当前
session下所有创建过的方法
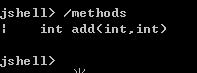
- 注意:还可以重新定义相同方法名和参数列表的方法,即对现有方法的修改(或覆盖)。
- 使用外部代码编辑器来编写
Java代码- 从外部文件加载源代码
HelloWorld.java - 使用
/open命令调用
- 从外部文件加载源代码

- 退出
jShell
异常处理之try-catch资源关闭(JDK7)
在JDK7之前,这样处理资源的关闭:
@Test
public void test01() {
FileWriter fw = null;
BufferedWriter bw = null;
try {
fw = new FileWriter("d:/1.txt");
bw = new BufferedWriter(fw);
bw.write("hello");
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (bw != null) {
bw.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if (fw != null) {
fw.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}JDK7的新特性
try()tryfinally
格式:
try(资源对象的声明和初始化){
业务逻辑代码,可能会产生异常
}catch(异常类型1 e){
处理异常代码
}catch(异常类型2 e){
处理异常代码
}- 在
try()中声明的资源, AutoCloseableCloseableclose()Closeable是AutoCloseable的子接口,Java7几乎把所有的资源类:包括文件IO的各种类、JDBC编程的Connection、Statement等接口都进行了改写,改写后资源类都实现了AutoCloseable或Closeable接口,并实现了close()方法try()final
举例:
//举例1
@Test
public void test02() {
try (
FileWriter fw = new FileWriter("d:/1.txt");
BufferedWriter bw = new BufferedWriter(fw);
) {
bw.write("hello");
} catch (IOException e) {
e.printStackTrace();
}
}
//举例2
@Test
public void test03() {
//从d:/1.txt(utf-8)文件中,读取内容,写到项目根目录下1.txt(gbk)文件中
try (
FileInputStream fis = new FileInputStream("d:/1.txt");
InputStreamReader isr = new InputStreamReader(fis, "utf-8");
BufferedReader br = new BufferedReader(isr);
FileOutputStream fos = new FileOutputStream("1.txt");
OutputStreamWriter osw = new OutputStreamWriter(fos, "gbk");
BufferedWriter bw = new BufferedWriter(osw);
) {
String str;
while ((str = br.readLine()) != null) {
bw.write(str);
bw.newLine();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}JDK9的新特性
trytry()tryfinally
格式:
A a = new A();
B b = new B();
try(a;b){
可能产生的异常代码
}catch(异常类名 变量名){
异常处理的逻辑
}举例:
@Test
public void test04() {
InputStreamReader reader = new InputStreamReader(System.in);
OutputStreamWriter writer = new OutputStreamWriter(System.out);
try (reader; writer) {
//reader是final的,不可再被赋值
// reader = null;
} catch (IOException e) {
e.printStackTrace();
}
}局部变量类型推断(JDK10)
局部变量的显示类型声明,常常被认为是不必须的,给一个好听的名字反而可以很清楚的表达出下面应该怎样继续,局部变量类型推断这个新特性允许开发人员省略不必要的局部变量类型声明,增强Java语言的体验性、可读性。
使用举例:
// 1.局部变量的实例化
var list = new ArrayList<String>();
var set = new LinkedHashSet<Integer>();
// 2.增强for循环中的索引
for (var v : list) {
System.out.println(v);
}
// 3.传统for循环中
for (var i = 0; i < 100; i++) {
System.out.println(i);
}
// 4. 返回值类型含复杂泛型结构
var iterator = set.iterator();
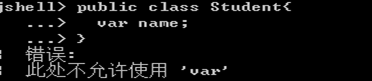
//Iterator<Map.Entry<Integer, Student>> iterator = set.iterator();- 声明一个成员变量
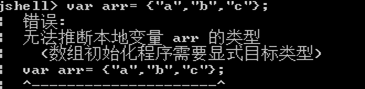
- 声明一个数组变量,并为数组静态初始化(省略
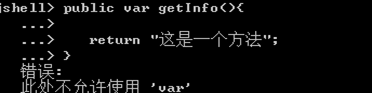
new的情况下) - 方法的返回值类型
- 方法的参数类型
- 没有初始化的方法内的局部变量声明
- 作为
catch块中异常类型 Lambda表达式中函数式接口的类型- 方法引用中函数式接口的类型
代码举例:
- 声明一个成员变量,并初始化值为
null
- 声明一个数组变量,并为数组静态初始化(省略
new的情况下)
- 没有初始化的方法内的局部变量声明

- 方法的返回值类型
- 方法的参数类型

- 构造器的参数类型
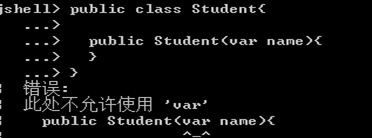
- 作为
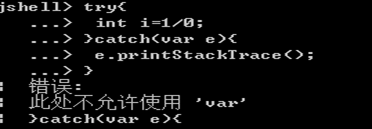
catch块中异常类型
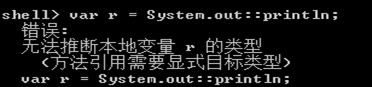
Lambda表达式中函数式接口的类型

- 方法引用中函数式接口的类型
varvar- 这不是
JavaScript,var并不会改变Java是一门静态类型语言的事实,编译器负责推断出类型,并把结果写入字节码文件,就好像是开发人员自己敲入类型一样
instanceof的模式匹配(JDK14JDK16)
JDK14中预览特性:
instanceof模式匹配通过提供更为简便的语法,来提高生产力。Java,实现更精确、简洁的类型安全的代码。
Java14之前旧写法:
if(obj instanceof String){
// 需要强转
String str = (String)obj;
str.contains(...)
// ...
}else{
//
}Java14新特性写法:
if(obj instanceof String str){
str.contains(...)
// ...
}else{
...
}举例:
@Test
public void test1() {
Object obj = new String("hello,Java14");
// 在使用 null 匹配instanceof时,返回都是false.
obj = null;
if (obj instanceof String) {
String str = (String) obj;
System.out.println(str.contains("Java"));
} else {
System.out.println("非String类型");
}
//举例1:
//新特性:省去了强制类型转换的过程
if (obj instanceof String str) {
System.out.println(str.contains("Java"));
} else {
System.out.println("非String类型");
}
}
// 举例2
class InstanceOf{
String str = "abc";
public void test(Object obj){
//此时的str的作用域仅限于if结构内
if(obj instanceof String str){
System.out.println(str.toUpperCase());
}else{
System.out.println(str.toLowerCase());
}
}
}
//举例3:
class Monitor {
private String model;
private double price;
// public boolean equals(Object o){
// if(o instanceof Monitor other){
// if(model.equals(other.model) && price == other.price){
// return true;
// }
// }
// return false;
// }
public boolean equals(Object o) {
return o instanceof Monitor other &&
model.equals(other.model) &&
price == other.price;
}
}JDK15中第二次预览:没有任何更改。
JDK16Java16
switch表达式(JDK12JDK14)
传统switch声明语句的弊端:
- 匹配是自上而下的,如果忘记写
break,后面的case语句不论匹配与否都会执行(case) - 所有的
case语句共用一个块范围,在不同的case语句定义的变量名不能重复 - 不能在一个
case里写多个执行结果一致的条件 - 整个
switch不能作为表达式返回值
//常见错误实现
switch(month){
case 3|4|5:
//3|4|5 用了位运算符,11 | 100 | 101结果是 111是7
System.out.println("春季");
break;
case 6|7|8:
//6|7|8用了位运算符,110 | 111 | 1000结果是1111是15
System.out.println("夏季");
break;
case 9|10|11:
//9|10|11用了位运算符,1001 | 1010 | 1011结果是1011是11
System.out.println("秋季");
break;
case 12|1|2:
//12|1|2 用了位运算符,1100 | 1 | 10 结果是1111,是15
System.out.println("冬季");
break;
default:
System.out.println("输入有误");
}JDK12
Java12将会对switch声明语句进行扩展,case L ->breakbreakbreakcase- 为保持兼容性,
case条件语句依然可使用字符:,但同一个switch结构里不能混用->和:,否则编译错误
举例:
// Java 12之前
public class SwitchTest {
public static void main(String[] args) {
int numberOfLetters;
Fruit fruit = Fruit.APPLE;
switch (fruit) {
case PEAR:
numberOfLetters = 4;
break;
case APPLE:
case GRAPE:
case MANGO:
numberOfLetters = 5;
break;
case ORANGE:
case PAPAYA:
numberOfLetters = 6;
break;
default:
throw new IllegalStateException("No Such Fruit:" + fruit);
}
System.out.println(numberOfLetters);
}
}
enum Fruit {
PEAR, APPLE, GRAPE, MANGO, ORANGE, PAPAYA;
}switch语句如果漏写了一个 break,那么逻辑往往就跑偏了,这种方式既繁琐,又容易出错。
// Java 12中
public class SwitchTest1 {
public static void main(String[] args) {
Fruit fruit = Fruit.GRAPE;
switch(fruit){
case PEAR -> System.out.println(4);
case APPLE,MANGO,GRAPE -> System.out.println(5);
case ORANGE,PAPAYA -> System.out.println(6);
default -> throw new IllegalStateException("No Such Fruit:" + fruit);
};
}
}更进一步:
public class SwitchTest2 {
public static void main(String[] args) {
Fruit fruit = Fruit.GRAPE;
int numberOfLetters = switch(fruit){
case PEAR -> 4;
case APPLE,MANGO,GRAPE -> 5;
case ORANGE,PAPAYA -> 6;
default -> throw new IllegalStateException("No Such Fruit:" + fruit);
};
System.out.println(numberOfLetters);
}
}JDK13
JDK13中引入了yield语句,用于返回值。这意味着,switch表达式(返回值)应该使用yield,switch语句(不返回值)应该使用breakyield和return的区别在于:return会直接跳出当前循环或者方法,而yield只会跳出当前switch块
在以前:
@Test
public void testSwitch1(){
String x = "3";
int i;
switch (x) {
case "1":
i=1;
break;
case "2":
i=2;
break;
default:
i = x.length();
break;
}
System.out.println(i);
}在JDK13中:
@Test
public void testSwitch2(){
String x = "3";
int i = switch (x) {
case "1" -> 1;
case "2" -> 2;
default -> {
yield 3;
}
};
System.out.println(i);
}或者
@Test
public void testSwitch3() {
String x = "3";
int i = switch (x) {
case "1":
yield 1;
case "2":
yield 2;
default:
yield 3;
};
System.out.println(i);
}JDK14中转正特性: 这是JDK12和JDK13中的预览特性,现在是正式特性了。
JDK17的预览特性:switch
旧写法:
static String formatter(Object o) {
String formatted = "unknown";
if (o instanceof Integer i) {
formatted = String.format("int %d", i);
} else if (o instanceof Long l) {
formatted = String.format("long %d", l);
} else if (o instanceof Double d) {
formatted = String.format("double %f", d);
} else if (o instanceof String s) {
formatted = String.format("String %s", s);
}
return formatted;
}模式匹配新写法:
static String formatterPatternSwitch(Object o) {
return switch (o) {
case Integer i -> String.format("int %d", i);
case Long l -> String.format("long %d", l);
case Double d -> String.format("double %f", d);
case String s -> String.format("String %s", s);
default -> o.toString();
};
}直接在switch上支持Object类型,这就等于同时支持多种类型,使用模式匹配得到具体类型,大大简化了语法量,这个功能很实用。
文本块(JDK15)
现实问题:在Java中,通常需要使用String类型表达HTML、XML、SQL、JSON等格式的字符串,。
JDK13
使用"""作为文本块的开始符和结束符,在其中就可以放置多行的字符串,不需要进行任何转义。因此,文本块将提高Java程序的可读性和可写性。
基本使用:
"""
line1
line2
line3
"""相当于:
"line1\nline2\nline3\n"或者一个连接的字符串:
"line1\n" +
"line2\n" +
"line3\n"如果字符串末尾不需要行终止符,则结束分隔符可以放在最后一行内容上:
"""
line1
line2
line3"""相当于
"line1\nline2\nline3"文本块可以表示空字符串,但不建议这样做,因为它需要两行源代码:
String empty = """
""";举例1:普通文本
原有写法:
String text1 = "The Sound of silence\n" +
"Hello darkness, my old friend\n" +
"I've come to talk with you again\n" +
"Because a vision softly creeping\n" +
"Left its seeds while I was sleeping\n" +
"And the vision that was planted in my brain\n" +
"Still remains\n" +
"Within the sound of silence";
System.out.println(text1);使用新特性:
String text2 = """
The Sound of silence
Hello darkness, my old friend
I've come to talk with you again
Because a vision softly creeping
Left its seeds while I was sleeping
And the vision that was planted in my brain
Still remains
Within the sound of silence
""";
System.out.println(text2);举例2:HTML语句
<html>
<body>
<p>Hello, 尚硅谷</p>
</body>
</html>将其复制到Java的字符串中,会展示成以下内容:
"<html>\n" +
" <body>\n" +
" <p>Hello, 尚硅谷</p>\n" +
" </body>\n" +
"</html>\n";即被自动进行了转义,这样的字符串看起来不是很直观,在JDK13中:
"""
<html>
<body>
<p>Hello, world</p>
</body>
</html>
""";举例3:SQL语句
select employee_id,last_name,salary,department_id
from employees
where department_id in (40,50,60)
order by department_id asc原有方式:
String sql = "SELECT id,NAME,email\n" +
"FROM customers\n" +
"WHERE id > 4\n" +
"ORDER BY email DESC";使用新特性:
String sql1 = """
SELECT id,NAME,email
FROM customers
WHERE id > 4
ORDER BY email DESC
""";举例4:JSON字符串
原有方式:
String myJson = "{\n" +
" \"name\":\"Song Hongkang\",\n" +
" \"address\":\"www.atguigu.com\",\n" +
" \"email\":\"shkstart@126.com\"\n" +
"}";
System.out.println(myJson);使用新特性:
String myJson1 = """
{
"name":"Song Hongkang",
"address":"www.atguigu.com",
"email":"shkstart@126.com"
}""";
System.out.println(myJson1);JDK14中二次预览特性(JDK15)
JDK14的版本主要增加了两个escape sequences(转义序列),分别是\与\s,\取消换行操作,\s表示一个空格。
举例:
public class Feature05 {
// jdk14新特性
@Test
public void test5(){
String sql1 = """
SELECT id,NAME,email
FROM customers
WHERE id > 4
ORDER BY email DESC
""";
System.out.println(sql1);
// \:取消换行操作
// \s:表示一个空格
String sql2 = """
SELECT id,NAME,email \
FROM customers\s\
WHERE id > 4 \
ORDER BY email DESC
""";
System.out.println(sql2);
}
}record(JDK16)
背景
早在2019年2月份,Java语言架构师Brian Goetz,曾写文抱怨“Java太啰嗦”或有太多的“繁文缛节”。他提到:开发人员想要创建纯数据载体类(plain data carriers)通常都必须编写大量低价值、重复的、容易出错的代码。如:构造函数、getter/setter、equals()、hashCode()以及toString()等。
以至于很多人选择使用IDE的功能来自动生成这些代码,还有一些开发会选择使用一些第三方类库,如:Lombok等来生成这些方法。
JDK14:神说要用record,于是就有了。实现一个简单的数据载体类,为了避免编写:构造函数,访问器,equals(),hashCode () ,toString ()等,Java14推出record。
recordfinalfinalpublic gethashcodeequalstoString。
具体来说:当用record声明一个类时,该类将自动拥有以下功能:
- 获取成员变量的简单方法,比如例题中的
name()和partner(),注意区别于平常getter()写法 - 一个
equals()方法的实现,执行比较时会比较该类的所有成员属性 - 重写
hashCode()方法 - 一个可以打印该类所有成员属性的
toString()方法
此外:
- 还可以在
record声明的类中定义:静态字段、静态方法、构造器或实例方法 recordabstract
举例1(旧写法):
class Point {
private final int x;
private final int y;
Point(int x, int y) {
this.x = x;
this.y = y;
}
int x() {
return x;
}
int y() {
return y;
}
public boolean equals(Object o) {
if (!(o instanceof Point)) return false;
Point other = (Point) o;
return other.x == x && other.y == y;
}
public int hashCode() {
return Objects.hash(x, y);
}
@Override
public String toString() {
return "Point{" +
"x=" + x +
", y=" + y +
'}';
}
}举例1(新写法):
record Point(int x, int y) { }举例2:
public record Dog(String name, Integer age) { }
public class Java14Record {
public static void main(String[] args) {
Dog dog1 = new Dog("牧羊犬", 1);
Dog dog2 = new Dog("田园犬", 2);
Dog dog3 = new Dog("哈士奇", 3);
System.out.println(dog1);
System.out.println(dog2);
System.out.println(dog3);
}
}举例3:
public class Feature07 {
@Test
public void test1(){
// 测试构造器
Person p1 = new Person("罗密欧",new Person("zhuliye",null));
// 测试toString()
System.out.println(p1);
// 测试equals():
Person p2 = new Person("罗密欧",new Person("zhuliye",null));
System.out.println(p1.equals(p2));
// 测试hashCode()和equals()
HashSet<Person> set = new HashSet<>();
set.add(p1);
set.add(p2);
for (Person person : set) {
System.out.println(person);
}
// 测试name()和partner(): 类似于getName()和getPartner()
System.out.println(p1.name());
System.out.println(p1.partner());
}
@Test
public void test2(){
Person p1 = new Person("zhuyingtai");
System.out.println(p1.getNameInUpperCase());
Person.nation = "CHN";
System.out.println(Person.showNation());
}
}
record Person(String name,Person partner) {
//还可以声明静态的属性、静态的方法、构造器、实例方法
public static String nation;
public static String showNation(){
return nation;
}
public Person(String name){
this(name,null);
}
public String getNameInUpperCase(){
return name.toUpperCase();
}
// 不可以声明非静态的属性 //报错
// private int id;
}
// 不可以将record定义的类声明为abstract的
//abstract record Order(){
//
//}
// 不可以给record定义的类声明显式的父类(非Record类)
//record Order() extends Thread{
//
//}JDK15中第二次预览特性
JDK16中转正特性
最终到JDK16中转正。
record记录不适合哪些场景:
record的设计目标是提供一种将数据建模为数据模型的好方法,它也不是JavaBeans的直接替代品,因为record的方法不符合JavaBeans的get标准;另外,JavaBeans通常是可变的,record是不可变的,尽管它们的用途有点像,但record并不会以某种方式取代JavaBean。
密封类(JDK17)
背景:
在Java中如果想让一个类不能被继承和修改,final。。Java15sealedsealed
JDK15的预览特性:
具体使用:
- 使用修饰符
sealed,可以将一个类声明为密封类,密封的类使用保留关键字permits列出可以直接扩展(即:extends)它的类 sealed修饰的类的机制具有传递性,它的子类必须使用指定关键字进行修饰,只能是final、sealed、non-sealed三者之一
举例:
public abstract sealed class Shape permits Circle, Rectangle, Square {...}
// final表示Circle不能再被继承了
public final class Circle extends Shape {...}
// non-sealed表示可以允许任何类继承
public non-sealed class Square extends Shape {...}
public sealed class Rectangle extends Shape permits TransparentRectangle, FilledRectangle {...}
public final class TransparentRectangle extends Rectangle {...}
public final class FilledRectangle extends Rectangle {...}JDK16二次预览特性
JDK17
API的变化
Optional类(JDK8)
到目前为止,臭名昭著的空指针异常是导致Java应用程序失败的最常见原因。以前,为了解决空指针异常,Google在著名的Guava项目引入了Optional类,。受到Google的启发,Optional类已经成为Java8类库的一部分。
Optional类(java.util.Optional) 是一个容器类,T,null。如果值存在,则isPresent()方法会返回true,调用get()方法会返回该对象。
Optional提供很多有用的方法,这样我们就不用显式进行空值检测。
Optional:static Optional empty():用来创建一个空的Optional实例static Optional of(T value):用来创建一个Optional实例,valuestatic Optional ofNullable(T value):用来创建一个Optional实例,value
Optional:boolean isPresent():判断Optional容器中的值是否存在void ifPresent(Consumer<? super T> consumer):OptionalConsumer
Optional:T get(): 如果调用对象包含值,返回该值,否则抛异常。T get()与of(T value)配合使用T orElse(T other):orElse(T other)与ofNullable(T value)配合使用,如果Optional容器中非空,就返回所包装值,如果为空,就用orElse(T other)other指定的默认值(备胎)代替T orElseGet(Supplier<? extends T> other):如果Optional容器中非空,就返回所包装值,如果为空,就用Supplier接口的Lambda表达式提供的值代替
JDK9~11:JDK9新增方法ifPresentOrElse(Consumer<? super T> action, Runnable emptyAction):value非空,执行参数1功能;如果value为空,执行参数2功能Optional or(Supplier<? extends Optional<? extends T>> supplier):value非空,返回对应的Optional;value为空,返回形参封装的OptionalStream stream():value非空,返回仅包含此value的Stream;否则,返回一个空的Stream
JDK10新增方法T orElseThrow(Supplier<? extends X> exceptionSupplier):如果Optional容器中非空,就返回所包装值,如果为空,就抛出你指定的异常类型代替原来的NoSuchElementException
JDK11新增方法boolean isEmpty():判断value是否为空
案例代码:
import java.util.Optional;
public class OptionalTest {
public static void main(String[] args) throws Exception {
// null字符串
String nullStr = null;
// 有值的字符串
String str = "weew12";
//static Optional empty() 创建空的Optional实例
Optional<Object> empty = Optional.empty();
// NoSuchElementException
// System.out.println(empty.get());
//static Optional of(T value) 创建非空Optional实例 value不能为空
// NullPointerException
// Optional<String> nullStr1 = Optional.of(nullStr);
Optional<String> str1 = Optional.of(str);
// 输出:Optional[weew12]
System.out.println(str1);
//static Optional ofNullable(T value) 创建Optional实例,value可以为空
Optional<String> nullStr1 = Optional.ofNullable(nullStr);
// 输出:Optional.empty
System.out.println(nullStr1);
Optional<String> str2 = Optional.ofNullable(str);
// 输出:Optional[weew12]
System.out.println(str2);
//boolean isPresent() 判断是否有值
Optional<String> nullStr11 = Optional.ofNullable(nullStr);
// 输出:false
System.out.println(nullStr11.isPresent());
Optional<String> str3 = Optional.ofNullable(str);
// 输出:true
System.out.println(str3.isPresent());
//void ifPresent(Consumer<? super T> consumer) 判断是否非空 非空就Consumer操作 否则不操作
Optional<String> nullStr2 = Optional.ofNullable(nullStr);
// 不操作
nullStr2.ifPresent(item -> System.out.println(item + "..."));
System.out.println();
Optional<String> str4 = Optional.ofNullable(str);
// 输出:weew12...
str4.ifPresent(item -> System.out.println(item + "..."));
//T get()
Optional<String> nullStr3 = Optional.ofNullable(nullStr);
// NoSuchElementException
// System.out.println(nullStr3.get());
Optional<String> str5 = Optional.ofNullable(str);
// 输出:weew12
System.out.println(str5.get());
//T orElse(T other)
String otherStr = "other";
Optional<String> nullStr4 = Optional.ofNullable(nullStr);
// 输出:other
System.out.println(nullStr4.orElse(otherStr));
Optional<String> str6 = Optional.ofNullable(str);
// 输出:weew12
System.out.println(str6.get());
//T orElseGet(Supplier<? extends T> other)
Optional<String> nullStr5 = Optional.ofNullable(nullStr);
// 输出:weew13
System.out.println(nullStr5.orElseGet(() -> "weew13"));
Optional<String> str7 = Optional.ofNullable(str);
// 输出:weew12
System.out.println(str7.orElseGet(() -> "weew13"));
//ifPresentOrElse(Consumer<? super T> action, Runnable emptyAction)
Optional<String> nullStr7 = Optional.ofNullable(nullStr);
// 输出:没有值
nullStr7.ifPresentOrElse(item -> System.out.println(item), () -> System.out.println("没有值"));
Optional<String> str9 = Optional.ofNullable(str);
// 输出:weew12
str9.ifPresentOrElse(item -> System.out.println(item), () -> System.out.println("没有值"));
//Optional or(Supplier<? extends Optional<? extends T>> supplier)
Optional<String> nullStr8 = Optional.ofNullable(nullStr);
// 输出:Optional.empty
System.out.println(nullStr8.or(() -> Optional.empty()));
Optional<String> str10 = Optional.ofNullable(str);
// 输出:Optional[weew12]
System.out.println(str10.or(() -> Optional.empty()));
//Stream stream()
Optional<String> nullStr9 = Optional.ofNullable(nullStr);
// 输出:0
System.out.println(nullStr9.stream().count());
Optional<String> str11 = Optional.ofNullable(str);
// 输出:1
System.out.println(str11.stream().count());
//T orElseThrow(Supplier<? extends X> exceptionSupplier)
Optional<String> nullStr6 = Optional.ofNullable(nullStr);
// Exception in thread "main" java.lang.Exception: 没有字符串
// System.out.println(nullStr6.orElseThrow(() -> new Exception("没有字符串")));
Optional<String> str8 = Optional.ofNullable(str);
// 输出:weew12
System.out.println(str8.orElseThrow(() -> new Exception("没有字符串")));
//boolean isEmpty()
Optional<String> nullStr10 = Optional.ofNullable(nullStr);
// 输出:true
System.out.println(nullStr10.isEmpty());
Optional<String> str12 = Optional.ofNullable(str);
// 输出:false
System.out.println(str12.isEmpty());
}
}String存储结构和API变更(JDK9)
背景:
Motivation The current implementation of the String class stores characters in a char array, using two bytes (sixteen bits) for each character. Data gathered from many different applications indicates that strings are a major component of heap usage and, moreover, that most String objects contain only Latin-1 characters. Such characters require only one byte of storage, hence half of the space in the internal char arrays of such String objects is going unused.
目前String类的实现是将字符存储在一个char数组中,每个字符使用两个字节(十六位)。从许多不同的应用程序收集的数据表明,字符串是堆内存使用的主要组成部分,并且StringLatin-1Stringchar
说明:
We propose to change the internal representation of the String class from a UTF-16 char array to a byte array plus an encoding-flag field. The new String class will store characters encoded either as ISO-8859-1/Latin-1 (one byte per character), or as UTF-16 (two bytes per character), based upon the contents of the string. The encoding flag will indicate which encoding is used.
我们提议将String类的内部表示从UTF-16字符数组改为字节数组加上一个编码标志字段。新的String类将根据字符串的内容,以ISO-8859-1/Latin-1(每个字符一个字节)或UTF-16(每个字符两个字节)的形式存储字符。编码标志将指示使用的是哪种编码。
结论:
Stringchar[]byte[]编码标记
拓展:StringBuffer与StringBuilder
那StringBuffer和StringBuilder是否仍无动于衷呢?
String-related classes such as AbstractStringBuilder, StringBuilder, and StringBuffer will be updated to use the same representation, as will the HotSpot VM's intrinsic string operations.
AbstractStringBuilderStringBuilderStringBufferHotSpot VM
JDK11新特性
isBlank():判断字符串是否为空白strip():去除首尾空白stripTrailing():去除尾部空格stripLeading():去除首部空格repeat():复制字符串lines().count():行数统计
public class Jdk11NewStringMethods {
public static void main(String[] args) {
// isBlank()
// true
System.out.println("".isBlank());
// false
System.out.println("weew12".isBlank());
// strip()
// weew12
System.out.println(" weew12 ".strip());
// stripTrailing()
// weew12
System.out.println(" weew12 ".stripTrailing());
// stripLeading()
// weew12
System.out.println(" weew12 ".stripLeading());
// repeat(3)
// weew12weew12
System.out.println("weew12".repeat(2));
// lines().count()
String s = """
123
456
789
""";
// 3
System.out.println(s.lines().count());
}
}StringConstableJDK12新特性
String源码:
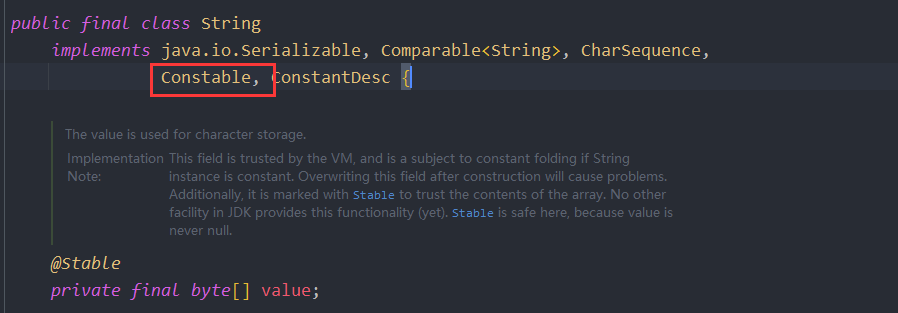
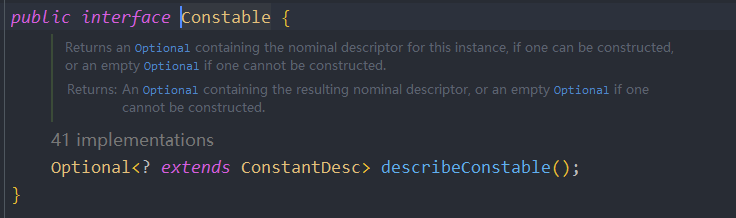
Java12 String的实现源码:
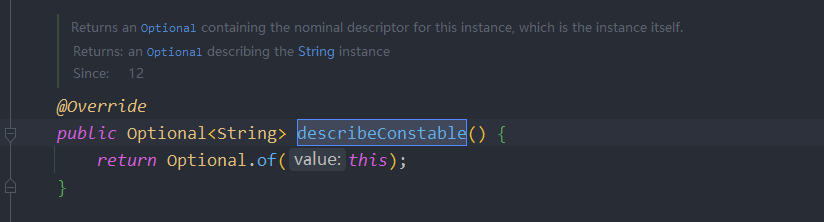
其实就是调用Optional.of方法返回一个Optional类型。
案例代码:
String name = "weew12";
Optional<String> s = name.describeConstable();
// 输出:weew12
System.out.println(s.get());String(JDK12新特性)
public <R> R transform(Function<? super String,? extends R> f)
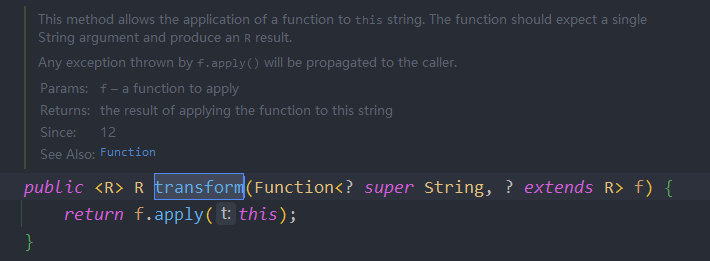
案例代码:
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
import java.lang.String;
public class Jdk12String {
public static void main(String[] args) {
String transform = "weew12".transform(String::toUpperCase);
// WEEW12
System.out.println(transform);
String transform1 = "weew 12".transform(String::toUpperCase).transform(str -> str.split(" ")[0]);
// WEEW
System.out.println(transform1);
List<String> list = List.of("Java", "Python", "C++");
ArrayList<String> list2 = new ArrayList<>();
list.forEach(item -> list2.add(
item.transform(String::toUpperCase)
.transform(e -> "Hello, " + e)
));
// Hello, JAVA
// Hello, PYTHON
// Hello, C++
list2.forEach(System.out::println);
}
}标记删除Applet API(JDK17)
Applet API提供了一种将Java AWT/Swing控件嵌入到浏览器网页中的方法。不过,目前 Applet 已经被淘汰。大部分人可能压根就没有用过 Applet。
Applet API实际上是无用的,因为所有Web浏览器供应商都已删除或透露计划放弃对Java浏览器插件的支持,Java9的时候,Applet API已经被标记为过时,Java17的时候终于标记为删除了。
具体如下:
java.applet.Applet
java.applet.AppletStub
java.applet.AppletContext
java.applet.AudioClip
javax.swing.JApplet
java.beans.AppletInitializer其它结构变化
UnderScore(下划线)使用的限制(JDK9)
在Java8中,标识符可以独立使用_来命名:
String _ = "hello";
System.out.println(_);但是,在Java9中规定_不再可以单独命名标识符了,如果使用,会报错:
更简化的编译运行程序(JDK11)
// 编译
javac JavaStack.java
// 运行
java JavaStack以前,要运行一个Java源代码必须先编译,再运行。而在Java11版本中,通过一个java命令就直接搞定了,如下所示:
java JavaStack.java注意:执行源文件中的第一个类,第一个类必须包含主方法。
GC方面新特性
GC是Java主要优势之一。 然而,当GC停顿太长,就会开始影响应用的响应时间。随着现代系统中内存不断增长,用户和程序员希望JVM能够以高效方式充分利用内存,并且无需长时间的GC暂停时间。
G1 GC
JDK9以后默认的垃圾回收器是G1GC。
JDK10: G1Full GC
G1最大的亮点就是可以尽量的避免full gc。但毕竟是“尽量”,在有些情况下,G1就要进行full gc了,比如如果它无法足够快的回收内存的时候,它就会强制停止所有的应用线程然后清理。
在Java10之前,一个单线程版的标记-清除-压缩算法被用于full gc。为了尽量减少full gc带来的影响,在Java10中,就把之前的那个单线程版的标记-清除-压缩的full gc算法改成了支持多个线程同时full gc。这样也算是减少了full gc所带来的停顿,从而提高性能。
可以通过-XX:ParallelGCThreads参数来指定用于并行GC的线程数。
JDK12:G1 Mixed GC
JDK12:G1
Shenandoah GC
JDK12:Shenandoah GCGC
Shenandoah垃圾回收器是Red Hat在2014年宣布进行的一项垃圾收集器研究项目Pauseless GC的实现,旨在针对JVM上的内存收回实现低停顿的需求。据Red Hat研发Shenandoah团队对外宣称,Shenandoah200 MB200 GB。
Shenandoah GC主要目标是99.9%的暂停小于10ms,暂停与堆大小无关等。
这是一个实验性功能,不包含在默认Oracle的OpenJDK版本中。
Shenandoah开发团队在实际应用中的测试数据:
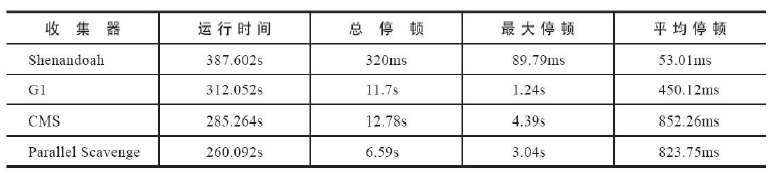
JDK15:Shenandoah
ShenandoahJDK12,该算法通过与正在运行的Java线程同时进行疏散工作来减少GC暂停时间。Shenandoah的暂停时间与堆大小无关,无论堆栈是200 MB还是200 GB,都具有相同的一致暂停时间。
Shenandoah在JDK12被作为experimental引入,在JDK15变为Production;之前需要通过-XX:+UnlockExperimentalVMOptions、-XX:+UseShenandoahGC来启用,现在只需要-XX:+UseShenandoahGC即可启用。
革命性的ZGC
JDK11:ZGC
ZGC,这应该是JDK11最为瞩目的特性,没有之一。
ZGC是一个 region 的垃圾收集器。
ZGC的设计目标:
支持TB级内存容量,暂停时间低(<10ms),对整个程序吞吐量的影响小于15%。 将来还可以扩展实现机制,以支持不少令人兴奋的功能,例如:多层堆(即:热对象置于DRAM和冷对象置于NVMe闪存),或压缩堆。
JDK13:ZGC
JDK14:ZGC on macOSwindows
JDK14之前,ZGC仅Linux才支持。现在mac或Windows上也能使用ZGC了,示例如下:XX:+UnlockExperimentalVMOptions -XX:+UseZGC
ZGC与Shenandoah目标高度相似,在尽可能对吞吐量影响不大的前提下,实现在任意堆内存大小下都可以把垃圾收集的停顿时间限制在十毫秒以内的低延迟
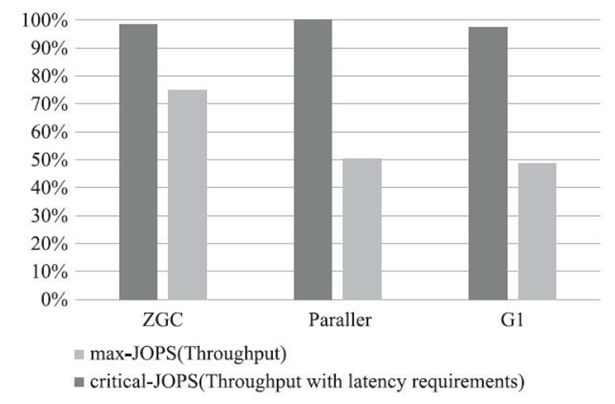
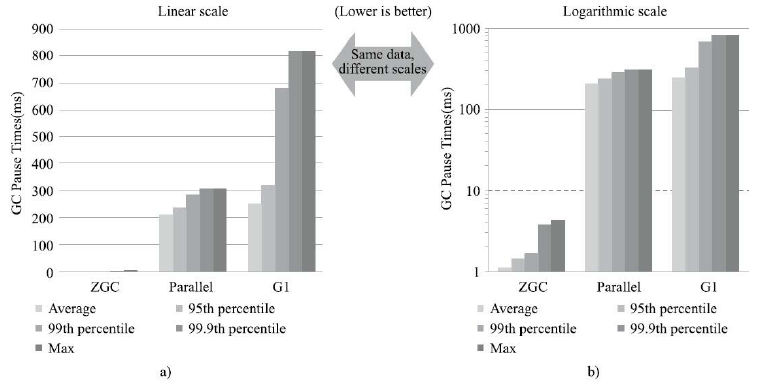
JDK15:ZGC
ZGC是Java11引入的新的垃圾收集器,经过了多个实验阶段,自此终于成为正式特性。但是这并不是替换默认的GC,默认的GC仍然还是G1,之前需要通过-XX:+UnlockExperimentalVMOptions、-XX:+UseZGC来启用ZGC,现在只需要-XX:+UseZGC就可以。
ZGC的性能已经相当亮眼,用“令人震惊、革命性”来形容不为过,未来将成为服务端、大内存、低延迟应用的首选垃圾收集器。
怎么形容Shenandoah和ZGC的关系呢?异同点大概如下:
- 相同点:性能几乎可认为是相同的
- 不同点:
ZGC是Oracle JDK的,根正苗红,而Shenandoah只存在于OpenJDK中,因此使用时需注意你的JDK版本
JDK16:ZGC
在线程的堆栈处理过程中,总有一个制约因素就是safepoints,在safepoints这个点,Java的线程是要暂停执行的,从而限制了GC的效率。
回顾:在之前需要GC的时候,需要所有的线程都暂停下来,这个暂停的时间称为:Stop The World,
为了实现STW这个操作,JVM需要为每个线程选择一个点停止运行,这个点叫做安全点Safepoints,
ZGCJavaGC safepointsJava