《Go Cookbook CN》系列 14:常见队列/栈/集合/链表/堆/图全实现
本文聚焦Go语言中未直接提供的常见数据结构,系统讲解队列、栈、集合、链表、堆、图的核心概念,并基于Go的切片、映射等基础结构从零实现这些数据结构的核心方法。通过本文学习,你将掌握各数据结构的设计逻辑与落地技巧,解决日常开发中各类数据存储与处理的场景需求。
【本篇核心收获】
- 掌握队列、栈、集合、链表、堆、图的核心定义与典型应用场景
- 能独立实现Go版队列(入队/出队/Peek)、栈(入栈/出栈/Peek)的完整逻辑
- 理解集合的数学运算(并集/交集/差集/子集)并完成Go实现
- 学会单向链表的增删查、二叉堆的push/pop重排、加权图的节点/边管理
- 明确Go自定义数据结构的并发安全优化方向
14.0 概述
Go语言的基础数据结构仅包含结构体、数组、切片和映射,日常开发中常用的队列、栈、集合等数据结构未直接提供,但基于Go的基础结构可轻松实现。
本文覆盖的自定义数据结构包括:队列 (Queue)、栈 (Stack)、集合 (Set)、链表 (LinkedList)、堆 (Heap)、图 (Graph),所有实现均基于Go的数组/切片/映射,需注意:本文实现的所有数据结构均非并发安全(基础结构本身非并发安全),若需避免争用条件,可通过sync.RWMutex加锁实现。
术语说明
- 列表 (list):线性、有序的条目序列,Go的数组/切片均属于列表,条目称为“元素”;
- 图 (Graph):一组相互连接的条目,条目称为“节点 (node)”,节点间连接称为“边 (edge)”。
14.1 队列 (Queue)
14.1.1 核心概念
队列是先进先出 (FIFO) 的有序列表,新元素从尾部加入(入队),元素从头部移除(出队),典型应用场景包括缓冲区、排队系统。
队列核心方法:
- 入队 (Enqueue):添加元素到队列尾部;
- 出队 (Dequeue):移除并返回队列头部元素;
- 窥视 (Peek):获取头部元素但不移除;
- 大小 (Size):获取队列元素数量;
- 是否为空 (IsEmpty):检查队列是否无元素。
队列结构示意如下: 
14.1.2 Go实现方案
基于切片封装结构体,通过切片的追加/重新切片实现队列核心方法。
1. 定义队列结构体
type Queue struct { // 队列 (Queue) 结构体
elements []any // 切片 (slice),元素类型为任意类型
}2. 核心方法实现
入队 (Enqueue)
将元素追加到切片尾部(队列尾部):
func (q *Queue) Enqueue(el any) { // 入队 (Enqueue) 方法
q.elements = append(q.elements, el)
}出队 (Dequeue)
获取切片索引0的元素(队列头部),并重新切片移除该元素,空队列返回错误:
func (q *Queue) Dequeue() (el any, err error) {
if q.IsEmpty() { // 检查队列是否为空
err = errors.New("empty queue")
return // 如果队列为空,则返回错误
}
el = q.elements[0] // 获取索引为 0 的元素
q.elements = q.elements[1:] // 重新切片,将索引为 0 的元素从队列中删除
return
}窥视 (Peek)
返回队列头部元素但不移除,空队列返回错误:
func (q *Queue) Peek() (el any, err error) {
if q.IsEmpty() { // 检查队列是否为空
err = errors.New("empty queue")
return // 如果队列为空,则返回错误
}
el = q.elements[0] // 获取索引为 0 的元素
return
}辅助方法(Size/IsEmpty)
func (q *Queue) IsEmpty() bool {
return q.Size() == 0 // 如果队列大小为 0,则返回 true;否则,返回 false
}
func (q *Queue) Size() int {
return len(q.elements) // 返回队列中元素数量
}14.1.3 模块小结
队列基于切片实现,核心是利用切片的追加(入队)和重新切片(出队)操作,需注意空队列的错误处理,确保方法鲁棒性。
14.2 创建栈 (Stack)
14.2.1 核心概念
栈是后进先出 (LIFO) 的有序列表,新元素从顶部加入(入栈),元素从顶部移除(出栈),典型应用场景包括内存管理、递归函数、表达式求值、回溯。
栈核心方法:
- 入栈 (Push):添加元素到栈顶;
- 出栈 (Pop):移除并返回栈顶元素;
- 窥视 (Peek):获取栈顶元素但不移除;
- 大小 (Size):获取栈元素数量;
- 是否为空 (IsEmpty):检查栈是否无元素。
栈结构示意如下: 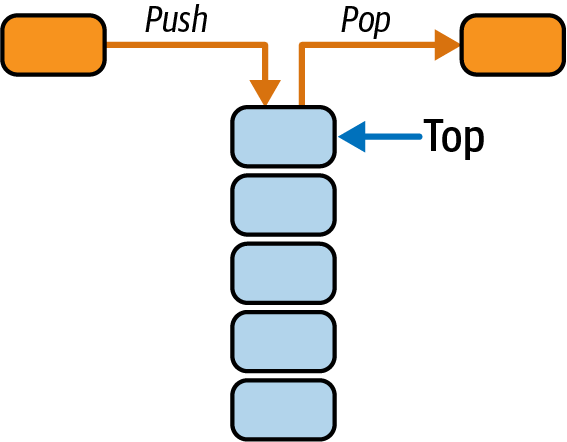
14.2.2 Go实现方案
基于切片封装结构体,将切片尾部视为栈顶,通过追加/重新切片实现核心方法。
1. 定义栈结构体
type Stack struct { // 栈 (Stack) 结构体
elements []any // 切片 (slice),元素类型为任意类型
}2. 核心方法实现
入栈 (Push)
将元素追加到切片尾部(栈顶):
func (s *Stack) Push(el any) { // 入栈方法
s.elements = append(s.elements, el) // 将元素追加到切片末尾,将切片末尾视为栈顶
}出栈 (Pop)
获取切片最后一个元素(栈顶),并重新切片移除该元素,空栈返回错误:
func (s *Stack) Pop() (el any, err error) { // 出栈方法
if s.IsEmpty() { // 检查栈结构是否为空
err = errors.New("empty stack") // 如果为空,则返回错误
return
}
el = s.elements[len(s.elements)-1]
s.elements = s.elements[:len(s.elements)-1] // 移除切片尾部的元素,即元素出栈
return
}窥视 (Peek)
返回栈顶元素但不移除,空栈返回错误:
func (s *Stack) Peek() (el any, err error) { // 窥视方法
if s.IsEmpty() { // 检查栈结构是否为空
err = errors.New("empty stack")
return
}
el = s.elements[len(s.elements)-1] // 返回切片的最后一个元素,即栈顶的元素
return
}辅助方法(Size/IsEmpty)
func (s *Stack) IsEmpty() bool {
return s.Size() == 0
}
func (s *Stack) Size() int {
return len(s.elements)
}14.2.3 模块小结
栈的实现逻辑与队列类似(均基于切片),核心差异在于栈以切片尾部为操作端(LIFO),队列以切片头部为出队端(FIFO),需注意空栈的错误处理。
14.3 创建集合 (Set)
14.3.1 核心概念
集合是无重复元素的无序数据结构,支持数学中的集合运算,典型应用场景包括去重、元素归属判断、集合运算(并集/交集等)。
集合核心方法/运算:
| 类型 | 方法/运算 | 说明 |
|---|---|---|
| 基础方法 | 添加 (Add) | 向集合添加新元素 |
| 基础方法 | 移除 (Remove) | 从集合中移除指定元素 |
| 基础方法 | 是否为空 (IsEmpty) | 检查集合是否无元素 |
| 基础方法 | 大小 (Size) | 获取集合元素数量 |
| 集合运算 | 具有 (Has) | 检查元素是否为集合成员 |
| 集合运算 | 并集 (Union) | 多个集合的所有元素(去重) |
| 集合运算 | 交集 (Intersection) | 多个集合的共有元素 |
| 集合运算 | 差集 (Difference) | 属于集合A但不属于集合B的元素 |
| 集合运算 | 子集 (IsSubset) | 检查集合B的所有元素是否都在集合A中(B是A的子集) |
14.3.2 Go实现方案
基于映射(Map)封装结构体,利用映射键的唯一性实现集合去重,键为集合元素,值为布尔类型(无实际意义)。
1. 定义集合结构体及初始化函数
映射使用前需初始化,因此需单独定义创建集合的函数:
type Set struct {
elements map[any]bool
}
func NewSet() Set { // 创建新集合的函数
return Set{elements: make(map[any]bool)}
}2. 基础方法实现
添加元素 (Add)
向映射中添加键(值设为true):
func (s *Set) Add(el any) { // 添加元素到集合的方法
s.elements[el] = true // 将元素添加到映射中,无需关心映射的值,简单地设为 true 即可
}移除元素 (Remove)
从映射中删除指定键:
func (s *Set) Remove(el any) { // 从集合中删除一个元素
delete(s.elements, el) // 实际上就是从内部映射中删除一个条目
}辅助方法(IsEmpty/Size/List)
func (s *Set) IsEmpty() bool {
return s.Size() == 0 // 如果内部映射大小为 0,则表示集合为空
}
func (s *Set) Size() int {
return len(s.elements) // 内部映射的元素数量就是集合的大小
}
func (s *Set) List() (list []any) {
for k := range s.elements { // 遍历内部映射的键
list = append(list, k) // 将键追加到切片 list 中即可
}
return
}3. 集合运算实现
成员判断 (Has)
检查映射中是否存在指定键(核心基础运算,其他运算依赖此方法):
func (s Set) Has(el any) (ok bool) {
_, ok = s.elements[el] // 检查内部映射中是否存在键名 el
return
}并集 (Union)
接收多个集合,返回包含所有集合元素的新集合(基于第一个集合的副本,避免修改原集合):
func (s *Set) Copy() (u Set) {
u = NewSet()
for k := range s.elements {
u.Add(k)
}
return
}
func Union(sets ...Set) (u Set) {
u = sets[0].Copy() // 为第一个集合创建副本,将该副本作为种子集合。
for _, set := range sets[1:len(sets)] { // 遍历其余的集合
for k := range set.elements { // 遍历其余的集合中的元素,并将得到的元素加入到种子集合中
u.Add(k)
}
}
return
}交集 (Intersection)
接收多个集合,返回所有集合的共有元素(基于第一个集合的副本,移除不符合条件的元素):
func Intersect(sets ...Set) (i Set) {
i = sets[0].Copy() // 为第一个集合创建副本,将该副本作为种子集合。
for k := range i.elements { // 遍历种子集合中的元素
for _, set := range sets[1:len(sets)] { // 遍历其余的集合
if !set.Has(k) { // 如果种子集合中的元素不在其余的某个集合中,则从种子集合中移除该元素
i.Remove(k)
}
}
}
return
}差集 (Difference)
返回“属于当前集合但不属于指定集合”的元素:
func (s Set) Difference(t Set) Set {
u := s.Copy()
for k := range t.elements { // 遍历给定集合中的元素
if u.Has(k) { // 如果给定集合中的元素也在集合 s 中,则从 s 中删除该元素
u.Remove(k) // 从集合 s 中移除该元素
}
}
return u // 返回最终的集合 s,即差集
}子集判断 (IsSubset)
检查当前集合是否是指定集合的子集:
func (s Set) IsSubset(t Set) bool {
for k := range s.elements {
// 遍历集合 s 中的元素
if !t.Has(k) {
// 如果集合 s 中的任一元素不在集合 t 中,则返回 false
return false // s 不是 t 的子集
}
}
return true // 如果集合 s 中的所有元素都在集合 t 中,则返回 true
}14.3.3 模块小结
集合基于映射实现,核心利用映射键的唯一性保证无重复元素;集合运算需基于副本操作,避免修改原集合,Has方法是所有集合运算的基础。
14.4 创建链表 (LinkedList)
14.4.1 核心概念
链表是线性元素集合,每个元素(节点)包含数据和指向下一节点的指针,元素无需连续存储,插入/删除效率高(仅需修改指针),随机访问效率低(需遍历)。
本文实现单向链表,核心方法:
- 添加 (Add):在链表头部添加新元素;
- 插入 (Insert):在指定元素后插入新元素;
- 删除 (Delete):删除指定元素;
- 查找 (Find):查找并返回指定元素;
- 辅助方法:Size/IsEmpty/List(转换为切片)。
链表结构示意如下: 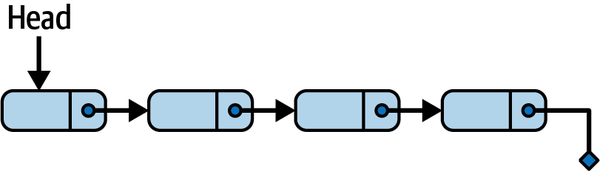
14.4.2 Go实现方案
定义两个结构体:Element(节点,包含值和下一节点指针)、LinkedList(链表,包含头节点指针和大小),利用泛型约束节点值支持排序。
1. 定义链表相关结构体
type Element[T constraints.Ordered] struct {
value T // 值字段,类型 T,必须满足 constraints.Ordered 约束(支持排序)
next *Element[T] // 指向链表中下一个元素的指针
}
type LinkedList[T constraints.Ordered] struct {
head *Element[T] // 指向链表的头部(第一个元素)
size int // 链表的大小
}2. 核心方法实现
添加元素 (Add)
在链表头部添加新节点:
// Add 将新元素添加到链表的头部
// 参数 el 是要添加到链表的新元素
func (l *LinkedList[T]) Add(el *Element[T]) {
// 如果链表为空(即头部为 nil),则新元素直接成为链表的头部
if l.head == nil {
l.head = el
} else {
// 如果链表不为空,将新元素的 next 指针指向当前的头部元素
el.next = l.head
// 然后,将链表的头部更新为新元素
l.head = el
}
// 链表的 size(大小)增加 1
l.size++
}插入元素 (Insert)
在指定标记元素后插入新节点,未找到标记返回错误:
// Insert 在链表中插入一个新元素,该元素被插入到值为 marker 的元素之后。
// 如果找到 marker,则新元素 el 被插入到 marker 后面,并返回 nil。如果没有找到 marker,则返回一个错误。
func (l *LinkedList[T]) Insert(el *Element[T], marker T) error {
// 从链表 l 头部开始遍历,直到链表的末尾
for current := l.head; current != nil; current = current.next {
if current.value == marker { // 检查当前节点的值是否为 marker
// 如果找到了 marker,设置新元素 el 的下一个节点为当前节点 current 的下一个节点
el.next = current.next
// 将当前节点 current 的下一个节点设置为新元素 el,完成插入操作
current.next = el
// 增加链表的元素数量
l.size++
// 插入成功,返回 nil
return nil
}
}
// 如果遍历完整个链表都没有找到 marker,返回一个错误
return errors.New("element not found")
}插入操作示意如下: 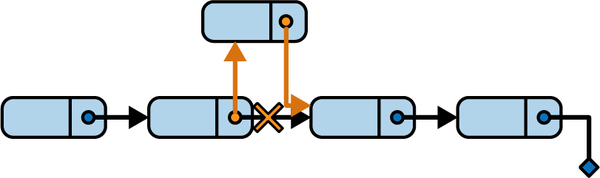
删除元素 (Delete)
删除指定节点,未找到返回错误(需跟踪前一节点):
// Delete 从链表中删除指定的元素 el。如果找到并删除了元素,则返回 nil;如果元素不在链表中,则返回一个错误。
func (l *LinkedList[T]) Delete(el *Element[T]) error {
// 初始化 prev 和 current 指针,都指向链表的头部
var prev *Element[T]
current := l.head
for current != nil { // 遍历链表直到 current 为 nil
if current.value == el.value { // 检查当前节点的值是否与要删除的元素 el 的值相等
if current == l.head {
l.head = current.next // 如果当前节点是头部节点,更新头部节点为当前节点的下一个节点
} else {
prev.next = current.next // 如果当前节点不是头部节点,将前一个节点的 next 指针指向当前节点的下一个节点
}
l.size-- // 减少链表的元素数量
return nil // 删除成功,返回 nil
}
prev = current // 更新 prev 指针为当前节点
current = current.next // 移动 current 指针到下一个节点
}
return errors.New("element not found") // 如果遍历完整个链表都没有找到元素,返回一个错误
}删除操作示意如下: 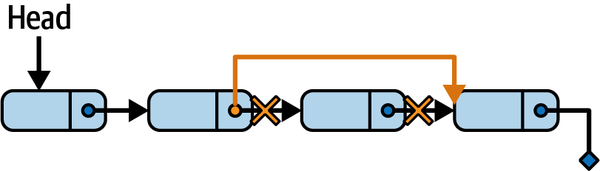
查找元素 (Find)
遍历链表查找指定值的节点,未找到返回错误:
func (l *LinkedList[T]) Find(value T) (el *Element[T], err error) {
// 从链表 l 头部开始遍历,直到链表的末尾
for current := l.head; current != nil; current = current.next {
if current.value == value {
el = current // 如果当前节点的值是否为要查找的值 value,则返回该节点
return
}
}
if el == nil {
// 如果遍历完整个链表都没有找到元素,返回一个错误
err = errors.New("element not found")
}
return
}3. 辅助方法实现
转换为切片 (List)
将链表节点存入切片(链表与切片相互独立,修改互不影响):
func (l *LinkedList[T]) List() (list []*Element[T]) {
if l.head == nil { // 如果链表为空,返回一个空切片
return []*Element[T]{}
}
// 遍历链表,将每个元素添加到切片中,并返回该切片
for current := l.head; current != nil; current = current.next {
list = append(list, current)
}
return
}辅助方法(Size/IsEmpty)
func (l *LinkedList[T]) IsEmpty() bool {
return l.size == 0
}
func (l *LinkedList[T]) Size() int {
return l.size
}14.4.3 模块小结
单向链表通过两个结构体实现,核心是指针的修改(添加/插入/删除),需注意遍历过程中跟踪前一节点(删除操作),以及空链表/未找到元素的错误处理;Go标准库container包提供双向链表实现,可作为扩展参考。
14.5 创建堆 (Heap)
14.5.1 核心概念
堆是满足堆属性的树状数据结构,分为两种类型:
- 最小堆:父节点键 ≤ 所有子节点键,根节点为最小元素;
- 最大堆:父节点键 ≥ 所有子节点键,根节点为最大元素。
堆典型应用为优先队列,核心方法:
- 入堆 (Push):添加节点到堆,并重排恢复堆属性;
- 出堆 (Pop):移除并返回堆顶节点,并重排恢复堆属性。
本文实现二叉最大堆(每个节点最多两个子节点),基于切片存储节点,节点索引关系:
- 左子节点索引 = 2 * 父节点索引 + 1;
- 右子节点索引 = 2 * 父节点索引 + 2;
- 父节点索引 = (子节点索引 - 1) / 2(整数除法)。
最大堆结构示意如下: 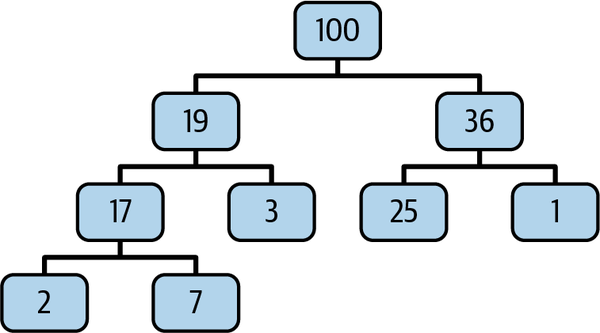
最大堆的切片布局示意如下: 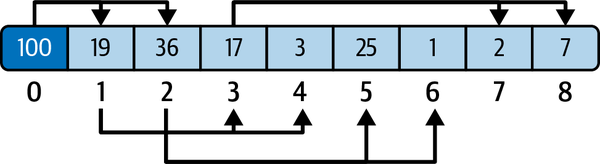
14.5.2 Go实现方案
基于切片封装结构体,入堆/出堆后通过递归/循环重排堆结构,保证堆属性。
1. 定义堆结构体及索引工具函数
type Heap[T constraints.Ordered] struct {
nodes []T // 存储堆中节点的切片
}
func parent(i int) int {
return (i - 1) / 2
}
func leftChild(i int) int {
return (2 * i) + 1
}
func rightChild(i int) int {
return (2 * i) + 2
}2. 核心方法实现
交换节点(辅助函数)
func (h *Heap[T]) swap(i, j int) {
h.nodes[i], h.nodes[j] = h.nodes[j], h.nodes[i]
}入堆 (Push)
将节点添加到切片尾部,然后向上冒泡重排(与父节点比较,最大堆则大于父节点则交换):
func (h *Heap[T]) Push(ele T) {
h.nodes = append(h.nodes, ele) // 将元素添加到堆的末尾(顶部)
i := len(h.nodes) - 1
for i > 0 && h.nodes[i] > h.nodes[parent(i)] { // 比较新节点与其父节点(对于最大堆)
h.swap(i, parent(i)) // 交换节点,将新节点上移到正确的位置
i = parent(i)
}
}重排堆(辅助递归函数)
出堆后,将最后一个节点移到堆顶,然后向下冒泡重排:
func (h *Heap[T]) rearrange(i int) {
largest := i
left, right, size := leftChild(i), rightChild(i), len(h.nodes)
if left < size && h.nodes[left] > h.nodes[largest] {
largest = left
}
if right < size && h.nodes[right] > h.nodes[largest] {
largest = right
}
if largest != i {
h.swap(i, largest)
h.rearrange(largest)
}
}出堆 (Pop)
移除并返回堆顶节点(切片索引0),将最后一个节点移到堆顶,然后重排:
func (h *Heap[T]) Pop() (ele T) {
if len(h.nodes) == 0 {
return ele
}
ele = h.nodes[0]
h.nodes[0] = h.nodes[len(h.nodes)-1]
h.nodes = h.nodes[:len(h.nodes)-1]
if len(h.nodes) > 0 {
h.rearrange(0)
}
return
}3. 辅助方法实现
func (h *Heap[T]) Size() int {
return len(h.nodes)
}
func (h *Heap[T]) IsEmpty() bool {
return h.Size() == 0
}14.5.3 模块小结
二叉堆基于切片实现,核心是入堆/出堆后的重排逻辑(向上/向下冒泡),保证堆属性;Go标准库container/heap包提供通用堆操作接口,可基于该接口实现自定义堆。
14.6 创建图 (Graph)
14.6.1 核心概念
图是由节点和边组成的非线性数据结构,本文实现加权无向图(边有权重,节点间边双向),核心方法:
- 添加节点 (AddNode):向图中添加节点;
- 添加边 (AddEdge):添加连接两个节点的加权边;
- 删除节点 (RemoveNode):从图中删除节点;
- 删除边 (RemoveEdge):从图中删除边。
加权图结构示意如下: 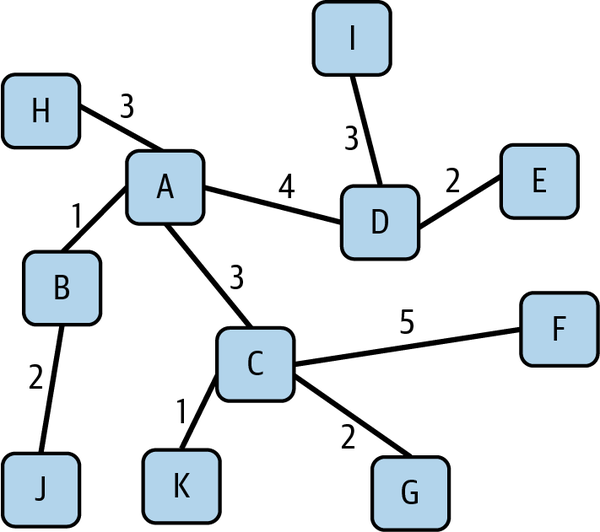
14.6.2 Go实现方案
定义三个结构体:Node(节点,含名称)、Edge(边,含目标节点指针和权重)、Graph(图,含节点切片和边映射),边映射的键为节点名,值为该节点关联的边切片。
1. 定义图相关结构体及初始化函数
type Node struct { // 表示图中的节点
name string // 节点名称
}
type Edge struct { // 表示图中连接节点的边
node *Node // 指向节点的指针
weight int // 边的权重
}
type Graph struct { // 表示一个加权图
Nodes []*Node // 图中包含的节点切片,元素类型为 *Node 指针
Edges map[string][]*Edge // 用映射表示图中的边,键为节点名,值为切片,元素类型为 *Edge 指针
}
func NewGraph() *Graph { // 定义一个函数,用于创建 Graph 结构体。该函数内部将执行
// Edges 字段的初始化
return &Graph{
Edges: make(map[string][]*Edge), // Edges 字段是映射类型,在使用之前需要先初始化
}
}2. 核心方法实现
添加节点 (AddNode)
将节点添加到图的节点切片:
func (g *Graph) AddNode(n *Node) {
g.Nodes = append(g.Nodes, n) // 将新节点添加到图中的节点切片中
}添加边 (AddEdge)
为两个节点添加双向加权边(无向图):
func (g *Graph) AddEdge(n1, n2 *Node, weight int) { // 添加边,需要三个参数,即两个节点和一个权重
g.Edges[n1.name] = append(g.Edges[n1.name], &Edge{n2, weight}) // 将边添加到映射 Edges 中,并与节点 n1 相关联
g.Edges[n2.name] = append(g.Edges[n2.name], &Edge{n1, weight}) // 将边添加到映射 Edges 中,并与节点 n2 相关联
}14.6.3 模块小结
加权无向图通过“节点切片+边映射”实现,核心是边的双向关联(无向图特性);需注意边映射的初始化,避免空指针错误。
【本篇核心知识点速记】
- 基础实现逻辑:队列/栈基于切片,集合基于映射,链表基于节点指针,堆基于切片+重排,图基于节点切片+边映射;
- 队列(FIFO):切片头部为出队端,尾部为入队端,核心方法Enqueue/Dequeue/Peek;
- 栈(LIFO):切片尾部为栈顶,核心方法Push/Pop/Peek;
- 集合:利用映射键唯一性去重,支持Add/Remove/Has及并集/交集/差集/子集运算;
- 单向链表:通过Element(节点)+LinkedList(链表)实现,核心是指针修改(Add/Insert/Delete);
- 二叉堆:基于切片存储,入堆向上冒泡、出堆向下冒泡重排,保证堆属性;
- 加权无向图:Node(节点)+Edge(边)+Graph(图)实现,边为双向关联,需初始化边映射;
- 并发安全:所有实现均非并发安全,可通过
sync.RWMutex加锁优化。