《Go语言实战》入门实战系列 02:程序架构全解——从项目结构到并发搜索实现
开篇引导
在上一篇文章中,我们了解了Go语言的设计哲学和核心特性。理论终需落地,本篇我们将通过一个完整的、可运行的Go程序,带你亲身体验Go语言的实际开发流程。这个程序实现了一个并发搜索引擎——从多个数据源(RSS、JSON等)拉取数据,根据搜索词进行匹配,并将结果展示在终端。
通过剖析这个程序,你将学习到:
- 如何组织一个真实Go项目的目录结构
- 如何使用包、类型、变量、函数和方法
- 如何启动和同步goroutine,使用通道进行通信
- 如何通过接口编写通用、可扩展的代码
- 如何处理常见的错误和日志
让我们从项目架构开始,一步步拆解这个完整的Go程序。
【本篇核心收获】
- 掌握Go项目标准目录结构设计
- 理解包导入机制、init函数的执行顺序和作用
- 掌握结构体定义、JSON/XML解码、指针使用
- 深入理解接口的设计与实现(隐式接口)
- 学习goroutine并发模式与WaitGroup同步机制
- 掌握通道(channel)在goroutine间传递数据的方式
- 了解闭包在并发场景下的使用陷阱及解决方案
1. 程序架构与项目结构
在深入代码之前,先理解程序的整体架构。图1清晰地展示了整个程序的执行流程:
图1:程序架构流程图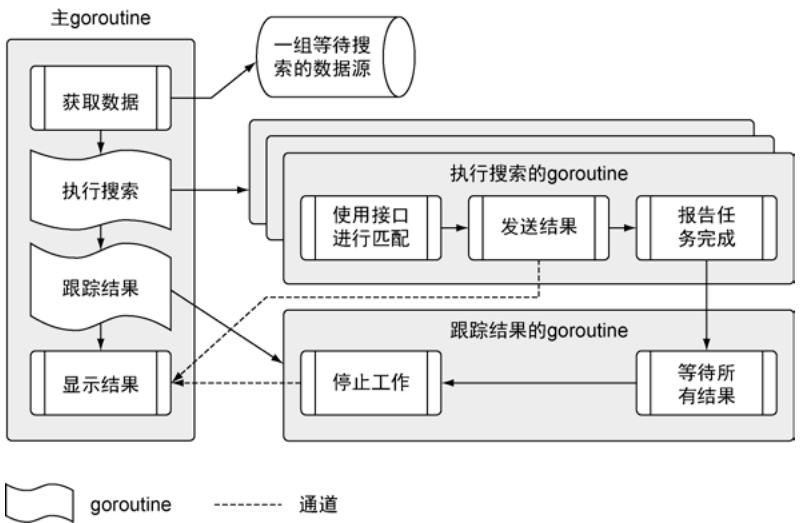
程序的执行分为以下几个核心阶段:
- 初始化:注册各种匹配器(默认匹配器、RSS匹配器等)
- 数据源加载:读取data.json文件,获取要搜索的数据源列表
- 并发搜索:为每个数据源启动一个goroutine,使用对应的匹配器执行搜索
- 结果收集:通过通道收集所有搜索结果
- 结果展示:在终端显示匹配的内容
1.1 项目目录结构
代码清单1展示了这个程序的完整项目结构:
cd $GOPATH/src/github.com/goinaction/code/chapter2
- sample
- data
data.json # 包含一组数据源配置
- matchers
rss.go # 搜索RSS源的匹配器实现
- search
default.go # 默认匹配器(兜底方案)
feed.go # 读取JSON数据文件
match.go # 定义Matcher接口和结果展示
search.go # 核心搜索控制逻辑
main.go # 程序入口设计要点:
- 每个文件夹对应一个包(package),包名与文件夹名相同
main包是程序入口,必须包含main函数- 通过包名实现代码的模块化隔离和复用
模块小结:Go项目的组织遵循“一个文件夹一个包”的原则,main包生成可执行文件,其他包作为库被引用。这种结构清晰明了,便于团队协作和代码复用。
2. main包——程序入口
2.1 main.go完整代码
代码清单2展示了程序的入口文件main.go:
01 package main
02
03 import (
04 "log"
05 "os"
06
07 _ "github.com/goinaction/code/chapter2/sample/matchers"
08 "github.com/goinaction/code/chapter2/sample/search"
09 )
10
11 // init在main之前调用
12 func init() {
13 // 将日志输出到标准输出
14 log.SetOutput(os.Stdout)
15 }
16
17 // main是整个程序的入口
18 func main() {
19 // 使用特定的项做搜索
20 search.Run("president")
21 }2.2 核心特性解析
包声明(第01行):
- 每个Go文件必须声明所属包名
main包是特殊包,编译后会生成可执行文件
导入机制(第03-09行):
import用于导入其他包的代码- 标准库包(如
log、os)直接从GOROOT中查找 - 第三方包从GOPATH中查找
匿名导入(第07行):
_ "github.com/goinaction/code/chapter2/sample/matchers"- 下划线
_表示“只初始化不引用” - 编译器会调用matchers包中所有代码文件的
init函数 - 用于注册匹配器,即使代码中没有显式使用该包的标识符
init函数(第11-15行):
- 每个包可以包含多个
init函数 init在main函数之前自动执行- 执行顺序:导入包的
init→ 当前包的init→main函数
main函数(第17-21行):
- 程序唯一入口,无参数无返回值
- 调用
search.Run启动核心搜索逻辑
模块小结:main包通过init函数完成初始化配置,通过匿名导入触发匹配器的注册,这种设计让程序启动时自动完成所有准备工作,main函数保持简洁。
3. search包——核心业务逻辑
search包是整个程序的核心,包含4个代码文件,各司其职。
3.1 search.go——主控制逻辑
包级变量与初始化
代码清单3展示了search.go的开头部分:
01 package search
02
03 import (
04 "log"
05 "sync"
06 )
07
08 // 注册用于搜索的匹配器的映射
09 var matchers = make(map[string]Matcher)包级变量(第09行):
- 声明在函数外,属于整个包
- 小写开头
matchers表示包内私有,外部包无法直接访问 make(map[string]Matcher)创建并初始化map,避免nil引用
命名规则:
- 大写字母开头:公开标识符,可被其他包访问
- 小写字母开头:私有标识符,仅包内可访问
Run函数——核心流程
Run函数是程序的“大脑”,完整流程见代码清单4:
11 // Run执行搜索逻辑
12 func Run(searchTerm string) {
13 // 获取需要搜索的数据源列表
14 feeds, err := RetrieveFeeds()
15 if err != nil {
16 log.Fatal(err)
17 }
18
19 // 创建一个无缓冲的通道,接收匹配后的结果
20 results := make(chan *Result)
21
22 // 构造一个waitGroup,以便处理所有的数据源
23 var waitGroup sync.WaitGroup
24
25 // 设置需要等待处理
26 // 每个数据源的goroutine的数量
27 waitGroup.Add(len(feeds))
28
29 // 为每个数据源启动一个goroutine来查找结果
30 for _, feed := range feeds {
31 // 获取一个匹配器用于查找
32 matcher, exists := matchers[feed.Type]
33 if !exists {
34 matcher = matchers["default"]
35 }
36
37 // 启动一个goroutine来执行搜索
38 go func(matcher Matcher, feed *Feed) {
39 Match(matcher, feed, searchTerm, results)
40 waitGroup.Done()
41 }(matcher, feed)
42 }
43
44 // 启动一个goroutine来监控是否所有的工作都做完了
45 go func() {
46 // 等候所有任务完成
47 waitGroup.Wait()
48
49 // 用关闭通道的方式,通知Display函数可以退出程序了
50 close(results)
51 }()
52
53 // 启动函数,显示返回的结果,并且在最后一个结果显示完后返回
54 Display(results)
55 }逐步拆解Run函数
步骤1:获取数据源列表(第14-17行)
feeds, err := RetrieveFeeds()
if err != nil {
log.Fatal(err)
}RetrieveFeeds()返回两个值:数据源切片和错误- Go的多返回值特性让错误处理更自然
log.Fatal输出错误并终止程序
步骤2:创建结果通道(第20行)
results := make(chan *Result)- 创建无缓冲通道,用于在goroutine间传递
*Result - 无缓冲通道要求发送和接收同时准备好,天然同步
步骤3:初始化WaitGroup(第23-27行)
var waitGroup sync.WaitGroup
waitGroup.Add(len(feeds))WaitGroup用于等待一组goroutine完成Add设置计数器为goroutine数量- 每个goroutine完成时调用
Done()递减计数器
步骤4:启动搜索goroutine(第30-42行)
for _, feed := range feeds {
matcher, exists := matchers[feed.Type]
if !exists {
matcher = matchers["default"]
}
go func(matcher Matcher, feed *Feed) {
Match(matcher, feed, searchTerm, results)
waitGroup.Done()
}(matcher, feed)
}关键点:
for range遍历feeds切片,_忽略索引- 从matchers map中获取对应的匹配器,若无则用默认匹配器
- 以参数形式传递
matcher和feed给匿名函数,避免闭包陷阱
避坑指南:闭包陷阱
❌ 错误写法:
for _, feed := range feeds {
matcher := matchers[feed.Type]
go func() {
Match(matcher, feed, searchTerm, results) // 使用外层变量
}()
}- 所有goroutine可能共享同一个
feed和matcher(循环的最后一个值) - 因为闭包捕获的是变量引用,而非值副本
✅ 正确写法(如代码所示):
go func(matcher Matcher, feed *Feed) {
Match(matcher, feed, searchTerm, results)
}(matcher, feed)- 将变量作为参数传入,每个goroutine获得独立副本
步骤5:监控goroutine与通道关闭(第45-52行)
go func() {
waitGroup.Wait()
close(results)
}()- 启动一个独立的监控goroutine
Wait()阻塞直到所有搜索goroutine完成- 关闭通道,通知接收方“没有更多数据了”
步骤6:显示结果(第54行)
Display(results)Display函数内部循环读取通道,直到通道关闭
3.2 feed.go——数据源加载
数据结构定义
代码清单5展示了Feed结构体:
01 package search
02
03 import (
04 "encoding/json"
05 "os"
06 )
07
08 const dataFile = "data/data.json"
09
10 // Feed包含我们需要处理的数据源的信息
11 type Feed struct {
12 Name string `json:"site"`
13 URI string `json:"link"`
14 Type string `json:"type"`
15 }结构体标签(Tag)(第12-14行):
json:"site"告诉JSON解码器将JSON中的site字段映射到Name- 实现了数据格式与结构体字段的解耦
RetrieveFeeds函数
代码清单6展示了数据读取和解码逻辑:
17 // RetrieveFeeds读取并反序列化源数据文件
18 func RetrieveFeeds() ([]*Feed, error) {
19 // 打开文件
20 file, err := os.Open(dataFile)
21 if err != nil {
22 return nil, err
23 }
24
25 // 当函数返回时关闭文件
26 defer file.Close()
27
28 // 将文件解码到一个切片里
29 var feeds []*Feed
30 err = json.NewDecoder(file).Decode(&feeds)
31
32 // 这个函数不需要检查错误,调用者会做这件事
33 return feeds, err
34 }defer语句(第26行):
defer file.Close()确保函数返回前关闭文件- 即使发生panic,defer也会执行
- 让资源管理代码紧邻资源获取代码,提高可读性
JSON解码(第28-30行):
json.NewDecoder(file)创建JSON解码器Decode(&feeds)将JSON数据解码到feeds切片- 传入
&feeds(指针),让解码器能修改feeds变量
数据文件示例(data.json):
[
{"site": "npr", "link": "http://www.npr.org/rss/rss.php?id=1001", "type": "rss"},
{"site": "cnn", "link": "http://rss.cnn.com/rss/cnn_world.rss", "type": "rss"},
{"site": "foxnews", "link": "http://feeds.foxnews.com/foxnews/world?format=xml", "type": "rss"},
{"site": "nbcnews", "link": "http://feeds.nbcnews.com/feeds/topstories", "type": "rss"}
]模块小结:feed.go负责数据源的加载和解析,通过结构体标签实现JSON到Go结构的自动映射,defer保证了文件资源的安全释放。
3.3 match.go——接口定义与结果展示
Matcher接口
代码清单7展示了Matcher接口和Result结构:
01 package search
02
03 import (
04 "log"
05 )
06
07 // Result保存搜索的结果
08 type Result struct {
09 Field string
10 Content string
11 }
12
13 // Matcher定义了要实现的新搜索类型的行为
14 type Matcher interface {
15 Search(feed *Feed, searchTerm string) ([]*Result, error)
16 }接口设计原则:
- 接口只包含一个方法,命名以
er结尾(Matcher、Reader、Writer) - 接口很小,专注于单一职责
- 实现接口不需要显式声明,只要实现所有方法即可
Match函数
代码清单8展示了执行搜索的函数:
19 // Match函数,为每个数据源单独启动goroutine来执行这个函数
20 // 并发地执行搜索
21 func Match(matcher Matcher, feed *Feed, searchTerm string, results chan<- *Result) {
22 // 对特定的匹配器执行搜索
23 searchResults, err := matcher.Search(feed, searchTerm)
24 if err != nil {
25 log.Println(err)
26 return
27 }
28
29 // 将结果写入通道
30 for _, result := range searchResults {
31 results <- result
32 }
33 }只写通道(第21行):
results chan<- *Result表示只能向通道发送数据- 提高类型安全,防止误接收
Display函数
代码清单9展示了结果展示函数:
35 // Display从每个单独的goroutine接收到结果后,在终端窗口输出
36 func Display(results chan *Result) {
37 // 通道会一直被阻塞,直到有结果写入
38 // 一旦通道被关闭,for循环就会终止
39 for result := range results {
40 fmt.Printf("%s:\n%s\n\n", result.Field, result.Content)
41 }
42 }range与通道:
for result := range results持续从通道读取,直到通道关闭- 通道为空时阻塞,有数据时唤醒
- 通道关闭时循环自动退出
3.4 default.go——默认匹配器
默认匹配器作为兜底方案,当找不到特定类型的匹配器时使用。
代码清单10展示了默认匹配器:
01 package search
02
03 // defaultMatcher实现了默认匹配器
04 type defaultMatcher struct{}
05
06 // init函数将默认匹配器注册到程序里
07 func init() {
08 var matcher defaultMatcher
09 Register("default", matcher)
10 }
11
12 // Search实现了默认匹配器的行为
13 func (m defaultMatcher) Search(feed *Feed, searchTerm string) ([]*Result, error) {
14 return nil, nil
15 }空结构体(第04行):
struct{}不占用任何内存- 适用于不需要存储状态的类型
方法接收者(第13行):
(m defaultMatcher)值接收者- 因为方法不修改接收者状态,使用值接收者即可
Register函数(第09行调用):
代码清单11展示了Register函数的实现(在search.go中):
59 // Register调用时,会注册一个匹配器,提供给后面的程序使用
60 func Register(feedType string, matcher Matcher) {
61 if _, exists := matchers[feedType]; exists {
62 log.Fatalln(feedType, "Matcher already registered")
63 }
64
65 log.Println("Register", feedType, "matcher")
66 matchers[feedType] = matcher
67 }模块小结:match.go定义了程序的扩展点(Matcher接口),default.go提供了默认实现,这种设计让程序可以轻松添加新的数据源类型,完全符合开闭原则。
4. RSS匹配器——具体实现
4.1 RSS数据结构
RSS匹配器位于matchers包中,通过匿名导入被程序加载。代码清单12展示了XML解码所需的结构体:
01 package matchers
02
03 import (
04 "encoding/xml"
05 "errors"
06 "fmt"
07 "log"
08 "net/http"
09 "regexp"
10
11 "github.com/goinaction/code/chapter2/sample/search"
12 )
13
14 type (
15 // item对应RSS中的<item>节点
16 item struct {
17 XMLName xml.Name `xml:"item"`
18 PubDate string `xml:"pubDate"`
19 Title string `xml:"title"`
20 Description string `xml:"description"`
21 Link string `xml:"link"`
22 GUID string `xml:"guid"`
23 GeoRssPoint string `xml:"georss:point"`
24 }
25
26 // image对应RSS中的<image>节点
27 image struct {
28 XMLName xml.Name `xml:"image"`
29 URL string `xml:"url"`
30 Title string `xml:"title"`
31 Link string `xml:"link"`
32 }
33
34 // channel对应RSS中的<channel>节点
35 channel struct {
36 XMLName xml.Name `xml:"channel"`
37 Title string `xml:"title"`
38 Description string `xml:"description"`
39 Link string `xml:"link"`
40 PubDate string `xml:"pubDate"`
41 LastBuildDate string `xml:"lastBuildDate"`
42 TTL string `xml:"ttl"`
43 Language string `xml:"language"`
44 ManagingEditor string `xml:"managingEditor"`
45 WebMaster string `xml:"webMaster"`
46 Image image `xml:"image"`
47 Item []item `xml:"item"`
48 }
49
50 // rssDocument对应RSS文档的根节点
51 rssDocument struct {
52 XMLName xml.Name `xml:"rss"`
53 Channel channel `xml:"channel"`
54 }
55 )
56
57 // rssMatcher实现了Matcher接口
58 type rssMatcher struct{}4.2 注册与初始化
代码清单13展示了RSS匹配器的注册:
60 // init将匹配器注册到程序里
61 func init() {
62 var matcher rssMatcher
63 search.Register("rss", matcher)
64 }由于main.go中使用匿名导入matchers包:
_ "github.com/goinaction/code/chapter2/sample/matchers"这个init函数会在main函数之前自动执行,完成RSS匹配器的注册。
4.3 retrieve方法——获取RSS数据
代码清单14展示了网络请求和XML解码:
114 // retrieve发送HTTP Get请求获取rss数据源并解码
115 func (m rssMatcher) retrieve(feed *search.Feed) (*rssDocument, error) {
116 if feed.URI == "" {
117 return nil, errors.New("No rss feed URI provided")
118 }
119
120 // 从网络获得rss数据源文档
121 resp, err := http.Get(feed.URI)
122 if err != nil {
123 return nil, err
124 }
125
126 // 一旦从函数返回,关闭响应链接
127 defer resp.Body.Close()
128
129 // 检查状态码
130 if resp.StatusCode != 200 {
131 return nil, fmt.Errorf("HTTP Response Error %d\n", resp.StatusCode)
132 }
133
134 // 将rss数据源文档解码到定义的结构类型里
135 var document rssDocument
136 err = xml.NewDecoder(resp.Body).Decode(&document)
137 return &document, err
138 }HTTP请求(第121行):
http.Get发起GET请求,Go标准库提供了简洁的HTTP客户端- 返回的
resp.Body需要在使用后关闭
defer resp.Body.Close()(第127行):
- 确保无论函数如何返回,响应体都会被关闭
- 防止资源泄漏
4.4 Search方法——匹配逻辑
代码清单15展示了搜索和匹配的核心逻辑:
69 // Search在文档中查找特定的搜索项
70 func (m rssMatcher) Search(feed *search.Feed, searchTerm string) ([]*search.Result, error) {
71 var results []*search.Result
72
73 log.Printf("Search Feed Type[%s] Site[%s] For Uri[%s]\n", feed.Type, feed.Name, feed.URI)
74
75 // 获取要搜索的数据
76 document, err := m.retrieve(feed)
77 if err != nil {
78 return nil, err
79 }
80
81 for _, channelItem := range document.Channel.Item {
82 // 检查标题部分是否包含搜索项
83 matched, err := regexp.MatchString(searchTerm, channelItem.Title)
84 if err != nil {
85 return nil, err
86 }
87
88 // 如果找到匹配的项,将其作为结果保存
89 if matched {
90 results = append(results, &search.Result{
91 Field: "Title",
92 Content: channelItem.Title,
93 })
94 }
95
96 // 检查描述部分是否包含搜索项
97 matched, err = regexp.MatchString(searchTerm, channelItem.Description)
98 if err != nil {
99 return nil, err
100 }
101
102 if matched {
103 results = append(results, &search.Result{
104 Field: "Description",
105 Content: channelItem.Description,
106 })
107 }
108 }
109
110 return results, nil
111 }正则匹配(第83行):
regexp.MatchString在字符串中搜索模式- 返回是否匹配和可能的错误
动态切片扩展(第90行):
append向切片追加元素- 如果容量不足,自动分配新内存
&search.Result{...}创建结构体指针
模块小结:RSS匹配器展示了如何实现一个完整的数据源适配器——通过HTTP获取数据,XML解码,正则匹配,最后将结果通过切片返回。整个流程清晰,错误处理完善。
5. 完整执行流程回顾
让我们串联所有组件,回顾程序的完整执行流程:
启动阶段:
- main包被加载,执行所有init函数
- default.go和rss.go的init函数分别注册默认匹配器和RSS匹配器
- main.go的init函数设置日志输出
- main函数被调用
数据准备:
search.Run("president")被调用RetrieveFeeds()读取data.json,返回Feed切片
并发搜索:
- 创建results通道和WaitGroup
- 为每个Feed启动goroutine
- 每个goroutine根据Feed.Type获取对应的Matcher
- 调用
Match函数执行搜索 - 结果写入results通道
- 调用
waitGroup.Done()
监控与输出:
- 监控goroutine等待所有搜索完成
- 关闭results通道
Display函数从通道读取结果并输出
程序终止:
- 所有结果输出完毕
- Display函数返回
- main函数返回,程序退出
6. 本篇核心知识点速记
- 包管理:每个文件夹一个包,main包生成可执行文件;大写标识符公开,小写私有
- init函数:在main之前执行,用于初始化注册;匿名导入
_触发init但不引用包 - 变量声明:
var声明零值变量,:=声明并初始化;make用于创建引用类型(map、slice、channel) - defer:延迟执行,用于资源释放(文件关闭、锁释放),确保即使panic也会执行
- 指针:通过
&取地址,*解引用;在函数间传递指针实现数据共享 - 接口:隐式实现,无需显式声明;小接口(单方法)命名以er结尾
- goroutine:使用
go关键字启动,轻量级并发单元;闭包传参避免变量共享陷阱 - WaitGroup:
Add设置计数,Done递减,Wait阻塞直到计数归零 - 通道:
make(chan Type)创建;<-发送和接收;close关闭通道;for range自动读取直到关闭 - 错误处理:函数返回
error,调用方检查;log.Fatal输出错误并退出 - JSON/XML解码:结构体标签定义映射;
NewDecoder().Decode()流式解码 - 切片:动态数组;
append追加元素;for range遍历
文末小结
本篇我们完整拆解了一个真实Go程序的架构和实现,从项目结构到并发控制,从接口设计到具体实现。通过这个示例,你应该已经感受到Go语言在并发编程、代码组织和可扩展性方面的独特魅力。
- 并发模型:goroutine+通道让并发代码既简单又安全
- 接口设计:隐式实现让代码解耦更彻底,扩展更灵活
- 标准库:net/http、encoding/json、encoding/xml等开箱即用
- 工具链:go build、go run、go fmt等让开发体验流畅