《Go Cookbook CN》系列 10:高效编解码——gob与自定义二进制格式全解析
在IoT设备、低带宽网络等场景下,文本格式(如JSON/CSV)因冗余性导致传输和存储效率低下,Go语言提供了gob原生二进制格式和自定义二进制编解码方案来解决这一问题。本文将从实战角度,全面讲解gob格式的编解码实现、自定义二进制格式的设计与编解码落地,并通过性能基准测试对比不同方案的优劣,帮助你掌握高性价比的二进制数据处理能力。
【本篇核心收获】
- 掌握Go语言中
encoding/gob包的使用,实现结构体与gob格式的双向编解码 - 理解自定义二进制格式的设计思路,基于
encoding/binary包完成手动/自动编解码 - 对比JSON、gob、自定义二进制格式的编解码性能与存储空间差异
- 掌握二进制编解码的性能优化技巧,适配低带宽/低存储的IoT场景需求
- 规避gob格式跨语言兼容、二进制字节序处理等常见坑点
1. 二进制编解码的应用背景
在处理I/O数据时,JSON、CSV等文本格式兼具人类可读性和机器兼容性,但冗余性成为其致命缺点:
- 传输效率:低带宽网络(如IoT设备的LP-WAN)下,冗余文本会增加传输耗时;
- 资源占用:IoT传感器、小型设备多为电池供电,内存/存储空间有限,文本格式的高占用会加剧资源消耗。
为解决上述问题,需将数据压缩至位/字节级别,常见方案包括BSON、Protocol Buffers、Apache Thrift等,而Go语言提供了原生的gob格式和灵活的自定义二进制编解码能力(基于encoding/binary包),本文将聚焦这两种方案的实战落地。
【模块小结】:二进制编解码的核心价值是降低数据体积、提升传输/存储效率,适配低带宽、低资源的IoT等场景,Go的gob和自定义二进制方案是该场景下的核心选择。
2. gob格式编解码实战
2.1 核心认知:gob格式的特性
gob是Go语言专属的二进制序列化格式,具备以下特性:
- 原生支持Go结构体序列化,无需手动定义格式;
- 编解码效率高于JSON,内存占用更优;
- 仅支持Go语言互通,跨语言场景需谨慎使用;
- 会存储结构体标签信息,导致数据体积略大于自定义二进制格式。
2.2 步骤1:将结构体编码为gob格式
场景:IoT电表数据采集,需将电表读数结构体序列化为gob格式,适配LP-WAN传输。
2.2.1 定义核心结构体
首先定义电表读数的结构体,包含唯一标识、电参数、时间戳等核心字段:
package main
import (
"log"
"os"
"time"
"encoding/gob"
)
type Meter struct { // 电表读数结构体,适配IoT场景的核心数据字段
Id uint32 // 电表唯一标识符(4字节)
Voltage float32 // 实时电压(伏特,4字节)
Current float32 // 实时电流(安培,4字节)
Energy uint32 // 累计能量(千瓦时,4字节)
Timestamp uint64 // 读数时间戳(纳秒级,8字节)
}2.2.2 构造测试数据
创建包含真实电表读数的结构体实例:
// 构造电表读数实例
var reading Meter = Meter{
Id: 123456,
Voltage: 229.5,
Current: 1.3,
Energy: 4321,
Timestamp: uint64(time.Now().UnixNano()),
}2.2.3 实现gob编码写入
编写通用写入函数,将结构体编码为gob格式并写入文件(模拟LP-WAN传输):
// write 将任意数据编码为gob格式并写入指定文件
func write(data interface{}, filename string) {
file, err := os.Create(filename) // 创建目标文件(实现io.Writer接口)
if err != nil {
log.Println("Cannot create file:", err)
return
}
defer file.Close() // 延迟关闭文件,避免资源泄漏
encoder := gob.NewEncoder(file) // 基于Writer创建gob编码器
err = encoder.Encode(data) // 编码结构体并写入文件
if err != nil {
log.Println("Cannot encode data to file:", err)
}
}
// 调用示例:将reading写入reading.gob文件
// write(reading, "reading.gob")【关键说明】:
gob.NewEncoder需接收实现io.Writer接口的对象(如文件、缓冲区);Encode方法会自动处理结构体的序列化,无需手动定义字段偏移量。
2.3 步骤2:将gob格式解码为结构体
编写通用读取函数,从gob文件中解码数据并填充至结构体:
// read 从指定文件读取gob数据并解码至目标结构体
func read(data interface{}, filename string) {
file, err := os.Open(filename) // 打开gob文件(实现io.Reader接口)
if err != nil {
log.Println("Cannot read file:", err)
return
}
defer file.Close()
decoder := gob.NewDecoder(file) // 基于Reader创建gob解码器
err = decoder.Decode(data) // 解码数据至目标结构体(需传入指针)
if err != nil {
log.Println("Cannot decode data:", err)
}
}
// 调用示例:解码reading.gob至reading实例
// read(&reading, "reading.gob")【避坑指南】:
- 解码时必须传入结构体指针(
&reading),否则无法填充数据; - 编解码的结构体字段需完全匹配(字段名、类型),否则会解码失败。
【模块小结】:gob编解码通过encoding/gob包的Encoder/Decoder实现,核心是绑定io.Writer/Reader,编解码时需注意结构体指针传递和字段一致性,该方案无需手动设计格式,但仅支持Go语言互通。
3. 自定义二进制格式的设计与编解码
3.1 核心认知:自定义二进制格式的设计思路
gob格式因携带结构体标签导致数据体积偏大(示例中gob占110字节),自定义二进制格式通过剔除标签、固定字段偏移量,可将数据体积压缩至最小(示例中仅24字节)。
Meter结构体的自定义二进制格式布局如图1所示: 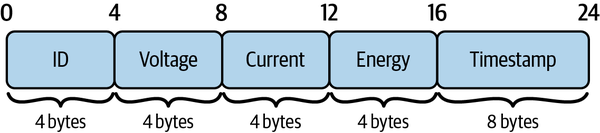
3.1.1 格式设计规则
基于Meter结构体的字段类型,设计固定长度的二进制格式(总计24字节):
| 字段 | 类型 | 字节数 | 偏移量(起始-结束) |
|---|---|---|---|
| Id | uint32 | 4 | 0-3 |
| Voltage | float32 | 4 | 4-7 |
| Current | float32 | 4 | 8-11 |
| Energy | uint32 | 4 | 12-15 |
| Timestamp | uint64 | 8 | 16-23 |
3.1.2 字节序选择
二进制编解码需指定字节序,常见类型:
- 大端序(BigEndian):高位字节在前,符合网络传输标准,本文统一使用;
- 小端序(LittleEndian):低位字节在前,适配部分硬件设备。
【避坑指南】:编解码需使用相同的字节序,否则会出现数据解析错误。
3.2 步骤1:自动编码为自定义二进制格式(基于binary.Write)
使用encoding/binary包的Write函数,自动将结构体写入二进制文件:
package main
import (
"log"
"os"
"encoding/binary"
)
// 复用前文定义的Meter结构体和reading实例
func main() {
file, err := os.Create("data.bin")
if err != nil {
log.Println("Cannot create file:", err)
return
}
defer file.Close()
// 将reading写入二进制文件(大端序)
err = binary.Write(file, binary.BigEndian, reading)
if err != nil {
log.Println("Cannot write to file:", err)
}
}【关键说明】:
binary.Write参数:Writer对象 → 字节序 → 待编码结构体;- 该方式无需手动处理字段偏移,但内存占用略高(88 B/op)。
3.3 步骤2:手动编码为自定义二进制格式(性能优化)
手动控制字段偏移和字节转换,提升编码性能(内存占用24 B/op,耗时仅15.28 ns/op):
package main
import (
"log"
"os"
"encoding/binary"
"math"
)
func main() {
file, err := os.Create("data.bin")
if err != nil {
log.Println("Cannot create file:", err)
return
}
defer file.Close()
// 创建24字节缓冲区,匹配自定义格式长度
buf := make([]byte, 24)
// 手动填充各字段(大端序)
binary.BigEndian.PutUint32(buf[0:], reading.Id) // Id:0-3字节
// float32需转换为IEEE 754二进制表示
binary.BigEndian.PutUint32(buf[4:], math.Float32bits(reading.Voltage)) // Voltage:4-7字节
binary.BigEndian.PutUint32(buf[8:], math.Float32bits(reading.Current)) // Current:8-11字节
binary.BigEndian.PutUint32(buf[12:], reading.Energy) // Energy:12-15字节
binary.BigEndian.PutUint64(buf[16:], reading.Timestamp) // Timestamp:16-23字节
// 写入缓冲区至文件
_, err = file.Write(buf)
if err != nil {
log.Println("Cannot write to file:", err)
}
}【核心优化点】:
- 预分配固定长度缓冲区,避免动态内存分配;
- 手动处理float32的IEEE 754转换,减少底层封装开销;
- 直接操作字节切片,无需反射解析结构体,性能提升显著。
3.4 步骤3:从自定义二进制格式解码为结构体
3.4.1 自动解码(基于binary.Read)
package main
import (
"log"
"os"
"encoding/binary"
"fmt"
)
func main() {
var data Meter // 用于接收解码数据的结构体
file, err := os.Open("data.bin")
if err != nil {
log.Println("Cannot read file:", err)
return
}
defer file.Close()
// 从二进制文件解码至结构体(大端序)
err = binary.Read(file, binary.BigEndian, &data)
if err != nil {
log.Println("Cannot read binary:", err)
}
fmt.Println("自动解码结果:", data)
}3.4.2 手动解码(性能最优)
package main
import (
"log"
"os"
"encoding/binary"
"math"
"fmt"
)
func main() {
var data Meter // 初始化空结构体
file, err := os.Open("data.bin")
if err != nil {
log.Println("Cannot read file:", err)
return
}
defer file.Close()
// 读取二进制数据至缓冲区
buf := make([]byte, 24)
_, err = file.Read(buf)
if err != nil {
log.Println("Cannot read from file:", err)
return
}
// 手动解析各字段(匹配编码时的偏移量和字节序)
data.Id = binary.BigEndian.Uint32(buf[:4])
// 将uint32转换回float32(还原IEEE 754格式)
data.Voltage = math.Float32frombits(binary.BigEndian.Uint32(buf[4:8]))
data.Current = math.Float32frombits(binary.BigEndian.Uint32(buf[8:12]))
data.Energy = binary.BigEndian.Uint32(buf[12:16])
data.Timestamp = binary.BigEndian.Uint64(buf[16:])
fmt.Println("手动解码结果:", data)
}【模块小结】:自定义二进制格式通过固定字段偏移量大幅降低数据体积,手动编解码虽代码量增加,但性能远超自动方式和gob/JSON,是IoT低资源场景的最优选择;需注意字节序统一和float32的IEEE 754转换。
4. 性能基准测试与方案对比
4.1 编码性能对比(darwin/arm64环境)
| 编码方案 | 执行次数/秒 | 耗时(ns/op) | 内存占用(B/op) | 内存分配次数(allocs/op) |
|---|---|---|---|---|
| JSON(json.NewEncoder) | 4835588 | 241.2 | 24 | 1 |
| gob(gob.NewEncoder) | 7738795 | 155.4 | 24 | 1 |
| 二进制自动编码(binary.Write) | 5537563 | 216.9 | 88 | 7 |
| 二进制手动编码 | 78357111 | 15.28 | 24 | 1 |
4.2 解码性能对比(darwin/arm64环境)
| 解码方案 | 执行次数/秒 | 耗时(ns/op) | 内存占用(B/op) | 内存分配次数(allocs/op) |
|---|---|---|---|---|
| JSON(json.NewDecoder) | 1000000 | 1023 | 101 | 5 |
| gob(gob.NewDecoder) | 13910449 | 81.27 | 96 | 2 |
| 二进制自动解码(binary.Read) | 14016166 | 85.29 | 24 | 1 |
| 二进制手动解码 | 100000000 | 1.099 | 0 | 0 |
4.3 存储空间对比
| 数据格式 | 存储空间(字节) | 核心优势 | 核心劣势 |
|---|---|---|---|
| JSON | ~100+ | 跨语言兼容、人类可读 | 冗余度高、性能差 |
| gob | 110 | 原生Go支持、编码性能优 | 跨语言不兼容、体积偏大 |
| 自定义二进制 | 24 | 体积最小、手动解码性能极致 | 需手动设计格式、跨语言适配成本高 |
【核心结论】:
- 编码性能:手动二进制 > gob > 自动二进制 > JSON;
- 解码性能:手动二进制 > gob > 自动二进制 > JSON;
- 存储空间:自定义二进制(24字节)远小于gob(110字节)和JSON;
- 场景适配:
- 跨语言场景:优先选JSON/Protocol Buffers;
- 纯Go场景、低资源要求:优先选gob;
- IoT低带宽/低存储场景:必选自定义手动二进制格式。
【模块小结】:不同二进制编解码方案需根据场景选择,性能与易用性、跨语言兼容性呈反比,手动自定义二进制是性能极致选择,gob是纯Go场景的平衡之选。
5. 避坑指南与最佳实践
5.1 常见坑点
- 字节序不统一:编解码必须使用相同的字节序(如均为BigEndian),否则解析出的数据完全错误;
- float32转换遗漏:手动编解码时,float32需通过
math.Float32bits/Float32frombits转换为uint32,直接读写会导致数据失真; - gob解码传值而非传指针:
gob.Decode需传入结构体指针,传值会导致解码后数据无法回写; - 自定义格式偏移量错误:字段偏移量需严格匹配设计规则,偏移错误会导致字段解析错位;
- 缓冲区长度不匹配:自定义二进制的缓冲区长度需与总字节数一致,过短会导致数据截断,过长会读取无效数据。
5.2 最佳实践
- 场景化选型:
- 快速开发、纯Go微服务:使用gob;
- IoT/低带宽场景:使用手动自定义二进制;
- 跨语言交互:使用Protocol Buffers(而非gob/自定义二进制);
- 性能优化:
- 手动二进制编解码时,预分配固定长度缓冲区,避免动态内存分配;
- 批量处理数据时,复用
Encoder/Decoder/缓冲区,减少重复创建开销;
- 兼容性保障:
- 自定义二进制格式需文档化字段偏移量、类型、字节序,便于多端适配;
- gob格式升级时,保持结构体字段向后兼容(新增字段加
omitempty,不删除原有字段)。
【模块小结】:二进制编解码的核心是平衡性能、易用性、兼容性,需规避字节序、类型转换、指针传递等坑点,根据场景选择最优方案。
【本篇核心知识点速记】
- gob编解码:基于
encoding/gob包,通过NewEncoder/NewDecoder绑定io.Writer/Reader,解码需传结构体指针,仅支持Go语言; - 自定义二进制设计:固定字段偏移量和字节序,总长度=各字段字节数之和(示例Meter为24字节);
- 自动二进制编解码:
binary.Write/binary.Read,无需手动处理偏移,但性能和内存占用略差; - 手动二进制编解码:直接操作字节切片,通过
math包处理float32转换,性能极致(解码仅1.099 ns/op); - 场景选型:跨语言用Protocol Buffers,纯Go用gob,低资源IoT用手动自定义二进制。